Dr. Clara Bird, Postdoctoral Scholar, OSU Department of Fisheries, Wildlife, and Conservation Sciences, GEMM Lab & LABIRINTO
In one of my first GEMM lab blogs (over six years ago!) I wrote that for my thesis I was going to, “…use the drone footage to analyze gray whale behavior and how it varies across space, time, and individual.”, and I’m happy to say that I more or less accomplished that goal. Now as I write my last blog for the GEMM lab, a whole PhD and postdoc later, I want to take this opportunity to share what we’ve learned about Pacific Coast Feeding Group (PCFG) gray whale behavior from my PhD and postdoc work.
A behavioral specialization
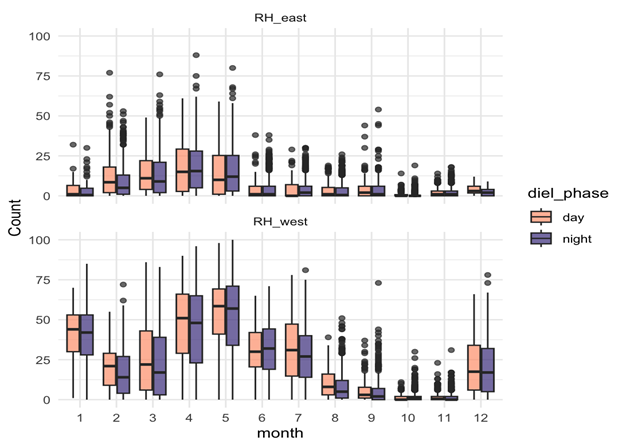
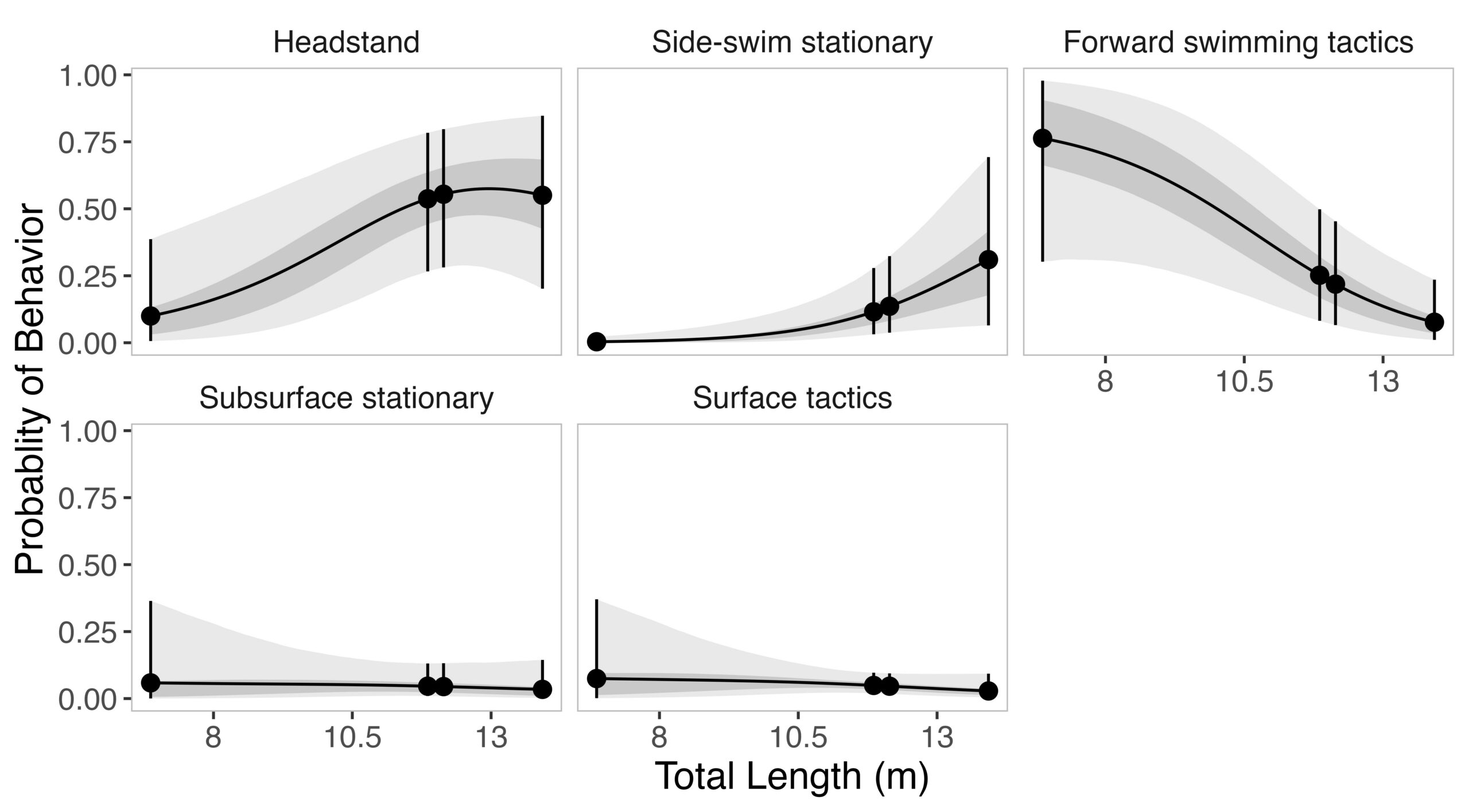
Given the impressive diversity of foraging tactics used by PCFG gray whales (Torres et al., 2018), a central question from the start was, “do all individuals use all behaviors, or is there variation in which whales use each behavior?”. This interest in individual specialization led to several blogs and became the question I asked in my first PhD chapter (read an introduction to specialization here and summaries of the drivers of specialization here and here). In my first chapter, I used drone data to study the relationship between individual behavior use, body length and condition, and habitat type. We found a strong relationship between foraging behavior and individual length (which is also a proxy for age). Longer, older, whales were more likely to feed using the headstanding tactic while shorter, younger, whales were more likely to feed using forward swimming tactics (Figure 1; Bird et al., 2024a). Together, these results suggest an ontogenetic shift (i.e., a shift associated with age) in foraging behavior use. Furthermore, we found that different tactics were more likely to be used in different habitats; headstanding was more likely to occur in reef habitats while the forward swimming tactics were more likely to occur in rock habitat. Overall, this chapter showed us that PCFG gray whale foraging behavior varies by length/age and habitat, indicating a lack of generalization across the group.
A behavioral adaptation
If you’ve ever watched gray whales off the coast and seen a large bubble rise to the surface, then you’ve seen a bubble blast! While we observed these bubble blasts, described as “underwater release of air that rises to surface and forms a circle/puka.” (Torres et al., 2018), fairly often in the field (Figure 2), we were never quite sure of their function, leading to my second chapter.

We initially wondered if bubble blasts served a prey corralling function (like humpback whale bubble nets), but the timing and location did not fit that idea. We instead wondered if bubble blasts were being used to regulate buoyancy. The whales we study forage in water nearly as shallow (<15 m) as they are long (~12 m), meaning that they must work against their buoyancy to dive. So, like a diver releasing air from their vest to sink, we hypothesized that these whales release air from their lungs (in the form of a bubble blast) to be able to dive more efficiently. Building on this idea, we specifically hypothesized that a whale would be more likely to bubble blast if they were bigger (i.e., because they had larger lungs) and fatter (i.e., they are more buoyant due to increased blubber). To test this hypothesis, we modeled the relationship between bubble blast use, total length, and body condition and found that the probability of an individual whale bubble blasting increased with total length and body condition. Furthermore, we found that whales who bubble blasted performed longer dives than those who did not, supporting our hypothesis that bubble blasts improved dive efficiency (Bird et al., 2024b).
Behavior and energetics
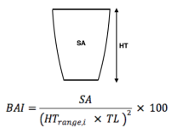
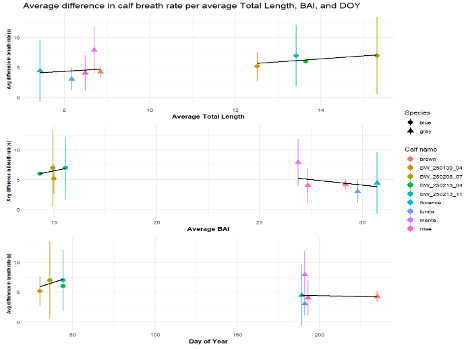
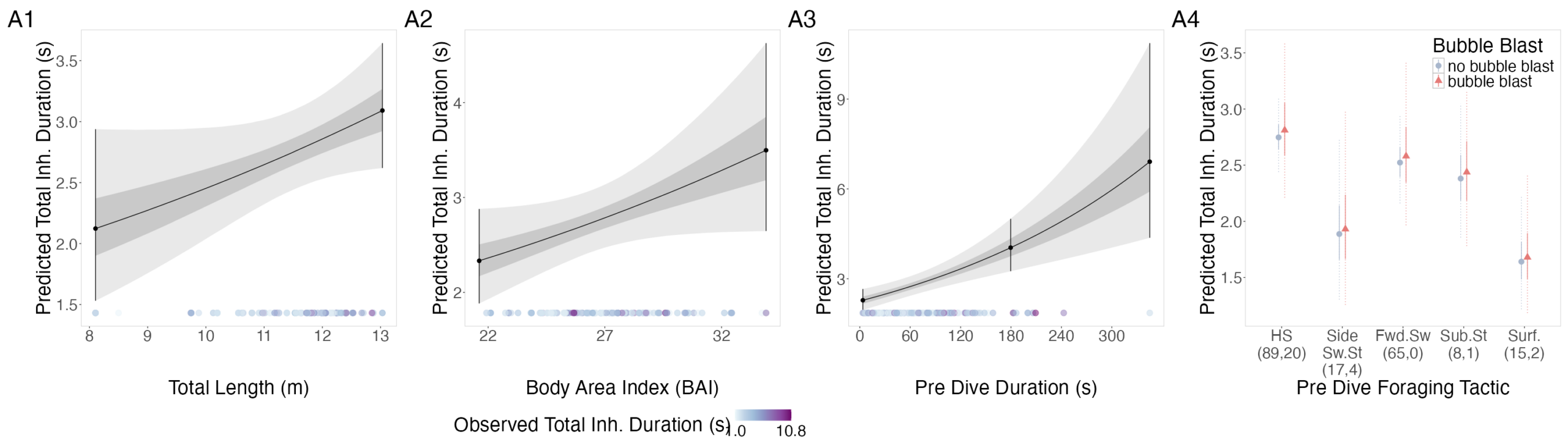
The interpretation of results from my first two chapters involved many questions regarding energetics. As we’ve described in previous blogs (here and here), it is important to understand how much energy different behaviors require because energetics helps us understand foraging success. Following the results of my first chapters, we wanted to better understand if different foraging behaviors cost different amounts of energy and if bubble blasts affected the energetic cost of a dive. To ask these questions we used individual breathing patterns as a proxy for energy expenditure (read more on the method here) and explored how breathing patterns were related to individual length, body condition, and behavior (including dive duration, foraging tactic, and bubble blast use). We found that the energetic cost of a dive increased with individual length, body condition, and dive duration (Figure 3.A1-3). Interestingly, we found no relationship between foraging tactic, bubble blast use and energetic expenditure (Bird et al., 2025; Figure 3.A4). However, my second chapter showed that both foraging behavior and bubble blast use affect dive duration (Bird et al., 2024b), indicating that effects of behavior on energetics come via the dive duration variable.
Social patterns
As a postdoctoral scholar I had the opportunity to pivot from PCFG foraging behavior to social behavior. We generally think of baleen whales as solitary animals with loose social structure when on their foraging grounds, including gray whales while in nearshore Oregon waters. But social structure is not well studied in gray whales and can provide important insight into how information or disease might pass through a population. To look for social patterns we first assigned whales to a group if they were seen within 10 minutes and 100 meters of each other; whales seen in the same group were determined to be “associated”. If we saw whales interact with each other (e.g., touch each other, swim in a synchronized movement) they were determined to be “interacting”. We then tallied the number of times each possible pair of whales had been seen associating and/or interacting. The higher the tally, the stronger the association. Using that dataset, we assessed if some whales were more central (i.e., had strong associations or more associations with other whales) than others and if centrality was related to sex and age. We also assessed if whales were more likely to associate with other whales of similar sex or age. Finally, we reviewed our notes from the field and drone footage and documented the kinds of social interactions we’ve observed. While we’re still wrapping up this work, I’m excited to share that we’ve found that gray whales have more social structure than previously thought, including relationships with age and sex, and documented several interesting social interactions (Figure 4). I am excited to see what more years of data collection reveal about their social patterns, especially with an emphasis on how they might be learning from each other.

Tying it all together
Looking ahead, I’m most curious to better understand how the PCFG successfully feed in this shallow habitat. The findings of my third chapter show that the energetic cost of foraging increases with body condition (Bird et al., 2025). I hypothesize that this increase is because it becomes physically more difficult to dive as they become more buoyant (due to the increased fat). So, while bubble blasts appear to be a behavioral adaptation to reduce buoyancy (Bird et al., 2024b), there could be a point at which a whale is too fat to continue feeding in this shallow environment. Could this be why PCFG gray whales are skinnier than the Eastern North Pacific (ENP) gray whales that feed in the deeper arctic waters (Torres et al., 2022)? Given recent evidence that the PCFG may be facing a possible population decline (Pirotta et al., 2025), these questions are more relevant than ever.
The one theme that weaves throughout all this work is the importance of individual variation. Thanks to our incredible dataset, built from years of hard work and accessible whales that keep returning to our study site, we are able to follow individuals over time and uncover the links between habitat, individual size, body condition and sex, behavior, energetics, and the whales themselves.
While I am sad to be leaving the GEMM lab, I am certainly proud of all that we have learned so far and excited to see what’s next (as an avid reader of the blog of course).
Did you enjoy this blog? Want to learn more about marine life, research, and conservation? Subscribe to our blog and get a weekly alert when we make a new post! Just add your name into the subscribe box below!
References
Bird CN, Pirotta E, New L, Bierlich KC, Donnelly M, Hildebrand L, Fernandez Ajó A, Torres LG. 2024a. Growing into it: evidence of an ontogenetic shift in grey whale use of foraging tactics. Animal Behaviour 214:121–135. DOI: 10.1016/j.anbehav.2024.06.004.
Bird CN, Pirotta E, New L, Bierlich KC, Hildebrand L, Fernandez Ajó A, Torres LG. 2024b. Bubble blasts! An adaptation for buoyancy regulation in shallow foraging gray whales. Ecology and Evolution 14:e70093. DOI: 10.1002/ece3.70093.
Bird CN, Pirotta E, New L, Cornelius JM, Sumich JL, Colson KM, Bierlich KC, Hildebrand L, Ajó AAF, Doron A, Torres LG. 2025. Size and body condition drive the energetic cost of a baleen whale foraging in shallow habitat. PeerJ13:e20247. DOI: 10.7717/peerj.20247.
Pirotta E, New L, Fernandez Ajó A, Bierlich KC, Bird CN, Buck CL, Hildebrand L, Hunt KE, Calambokidis J, Torres LG. 2025. Body size, nutritional state and endocrine state are associated with calving probability in a long-lived marine species. Journal of Animal Ecology 94:1–13. DOI: 10.1111/1365-2656.70068.
Torres LG, Bird CN, Rodríguez-González F, Christiansen F, Bejder L, Lemos L, Urban R J, Swartz S, Willoughby A, Hewitt J, Bierlich KC. 2022. Range-Wide Comparison of Gray Whale Body Condition Reveals Contrasting Sub-Population Health Characteristics and Vulnerability to Environmental Change. Frontiers in Marine Science 9:1–13. DOI: https://doi.org/10.3389/fmars.2022.867258.
Torres LG, Nieukirk SL, Lemos L, Chandler TE. 2018. Drone up! Quantifying whale behavior from a new perspective improves observational capacity. Frontiers in Marine Science 5:1–14. DOI: 10.3389/fmars.2018.00319.