By Morgan O’Rourke-Liggett, M.S., Oregon State University, Department of Fisheries, Wildlife, and Conservation Sciences, Geospatial Ecology of Marine Megafauna Lab
It is the end.
I graduated with a Master’s degree.
This journey began 10 years ago when I visited colleges as a high school junior.
Begin with the end in mind.
I knew I would major in science as an undergrad and focus on something more specific as a graduate student. Studying whales required a background in marine biology, which led to my undergraduate degree in oceanography with strong emphasis in fisheries and wildlife, policy, and ecology. My master’s degree was built on that and added specific skills in data collection, management, and analysis.
The last time I wrote a blog, I was sharing the details of the data management and intricacies of my master’s project. Part of what made that project so successful was knowing the end goal: we wanted to know the area surveyed based on visibility and a visual representation of it. This knowledge aided in the development of matrices for environmental conditions, assigning integer variables to text survey notes, and determining what toolboxes and packages would be the most appropriate for analysis.
As a visual learner, I like to sketch out what I am doing or draw it on a whiteboard in a concept board. This approach is something I have always done and was further reinforced as a necessary step in my programming classes early on in my master’s education. My professors would assign a problem that could be solved in programming by making a function or script of code. We were taught to write out what our end goals were and what inputs were available for the problem. From there, filling in what steps were needed would be added. That was a critical step that made writing many difficult Python and R for loops and functions easier to build.
This skill and mentality of “beginning with the end” in mind can also be useful in preparation for data collection. There are eleven common data types that are described with examples in Table 1. Understanding what data type is being collected could save several hours of data management and wrangling during the data analysis phase. From my experience in data analytics, some models yield more accurate results if the character data is manipulated to behave like an integer in R. Additionally, certain packages and toolboxes in R and GIS are only useful for certain data types.
Data Type
Definition
Example
Integer (int)
Numeric data without fractions
-707, 0, 707
Floating point (float) or Double
Numeric data with fractions
707.07, 0.7, 707.00
Character (char)
Single letter, digit, space, punctuation mark, symbol
a, !
String (str or text) or Complex
Sequence of characters, digits, or symbols
Hello, +1-999-666-3333
Boolean (bool) or Logical
True or false values
0 (false), 1 (true)
Enumerated type (enum)
Small set of predefined values that can be text or numerical
rock (0), jezz (1)
Array
List with a number of elements in a specific order
rock (0), jazz (1), blues (2), pop (3)
Data
Date in YYYY-MM-DD fomat
2021-09-28
Time
Time in hh:mm:ss format or a time interval between two events
12:00:59
Datetime
Stores a value of both YYYY-MM-DD hh:mm:ss
2021-09-28 12:00:59
Timestamp
Number of seconds that have elapsed since midnight, 1st January 1970 in UTC
1632855600
Table 1. Table of the eleven most common data types with a short definition and an example of the data type. Table inspired by (Choudhury 2022).
Beginning with the end in mind allows more clarity and strategies to be efficient and achieve your goal. It develops a better understanding of why each stage of data collection and analysis is important; why each stage in a career is important. It provides a road map for what will, undoubtedly, be an incredible learning experience.
Did you enjoy this blog? Want to learn more about marine life, research, and conservation? Subscribe to our blog and get a weekly message when we post a new blog. Just add your name and email into the subscribe box below.
By Morgan O’Rourke-Liggett, Master’s Student, Oregon State University, Department of Fisheries, Wildlife, and Conservation Sciences, Geospatial Ecology of Marine Megafauna Lab
Avid readers of the GEMM Lab blog and other scientists are familiar with the incredible amounts of data collected in the field and the informative figures displayed in our publications and posters. Some of the more time-consuming and tedious work hardly gets talked about because it’s the in-between stage of science and other fields. For this blog, I am highlighting some of the behind-the-scenes work that is the subject of my capstone project within the GRANITE project.
For those unfamiliar with the GRANITE project, this multifaceted and non-invasive research project evaluates how gray whales respond to chronic ambient and acute noise to inform regulatory decisions on noise thresholds (Figure 1). This project generates considerable data, often stored in separate Excel files. While this doesn’t immediately cause an issue, ongoing research projects like GRANITE and other long-term monitoring programs often need to refer to this data. Still, when scattered into separate long Excel files, it can make certain forms of analysis difficult and time-consuming. It requires considerable attention to detail, persistence, and acceptance of monotony. Today’s blog will dive into the not-so-glamorous side of science…data management and standardization!
Figure 1. Infographic for the GRANITE project. Credit: Carrie Ekeroth
Of the plethora of data collected from the GRANITE project, I work with the GPS trackline data from the R/V Ruby, environmental data recorded on the boat, gray whale sightings data, and survey summaries for each field day. These come to me as individual yearly spreadsheets, ranging from thirty entries to several thousand. The first goal with this data is to create a standardized survey effort conditions table. The second goal is to determine the survey distance from the trackline, using the visibility for each segment, and calculate the actual area surveyed for the segment and day. This blog doesn’t go into how the area is calculated. Still, all these steps are the foundation for finding that information so the survey area can be calculated.
The first step requires a quick run-through of the sighting data to ensure all dates are within the designated survey area by examining the sighting code. After the date is a three-letter code representing a different starting location for the survey, such as npo for Newport and dep for Depoe Bay. If any code doesn’t match the designated codes for the survey extent, those are hidden, so they are not used in the new table. From there, filling in the table begins (Figure 2).
Figure 2. A blank survey effort conditions table with each category listed at the top in bold.
Segments for each survey day were determined based on when the trackline data changed from transit to the sighting code (i.e., 190829_1 for August 29th, 2019, sighting 1). Transit indicated the research vessel was traveling along the coast, and crew members were surveying the area for whales. Each survey day’s GPS trackline and segment information were copied and saved into separate Excel workbook files. A specific R code would convert those files into NAD 1983 UTM Zone 10N northing and easting coordinates.
Those segments are uploaded into an ArcGIS database and mapped using the same UTM projection. The northing and easting points are imported into ArcGIS Pro as XY tables. Using various geoprocessing and editing tools, each segmented trackline for the day is created, and each line is split wherever there was trackline overlap or U shape in the trackline that causes the observation area to overlap. This splitting ensures the visibility buffer accounts for the overlap (Figure 3).
Figure 3. Segment 3 from 7/22/2019 with the visibility of 3 km portrayed as buffers. There are more than one because the trackline was split to account for the overlapping of the survey area. This approach accounts for the fact that this area where all three buffers overlap was surveyed 3 times.
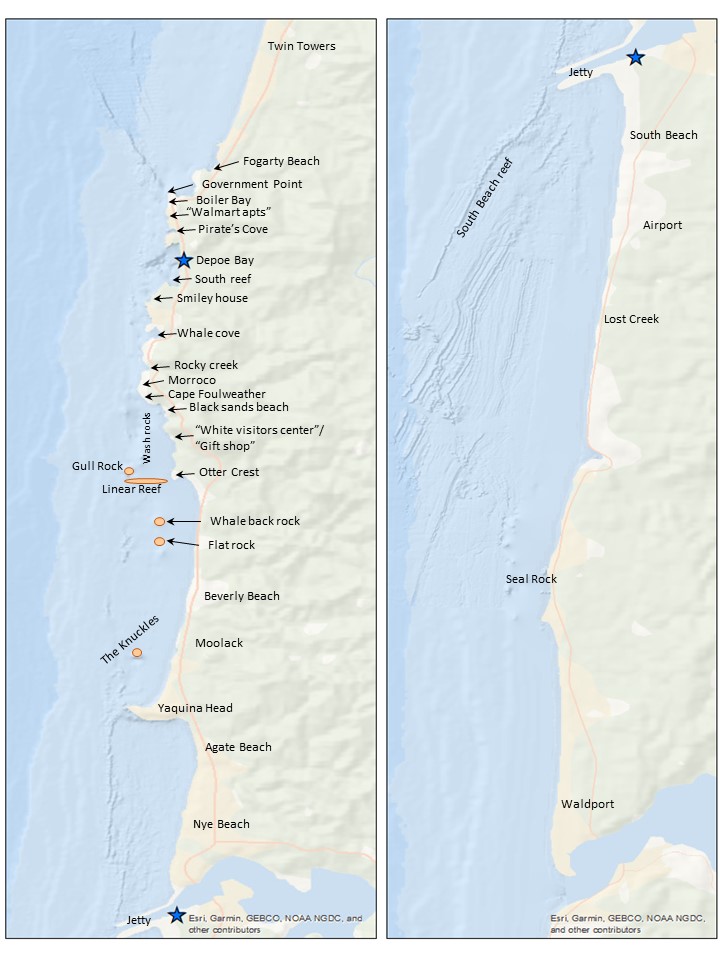
Once the segment lines are created in ArcGIS, the survey area map (Figure 4) is used alongside the ArcGIS display to determine the start and end locations. An essential part of the standardization process is using the annotated locations in Figure 4 instead of the names on the basemap for the location start and endpoints. This consistency with the survey area map is both for tracking the locations through time and for the crew on the research vessel to recognize the locations. The step assists with interpreting the survey notes for conditions at the different segments. The time starts and ends, and the latitude and longitude start and end are taken from the trackline data.
Figure 4. Map of the survey area with annotated locations (Created by L. Torres, GEMM Lab)
The sighting data includes the number of whales sighted, Beaufort Sea State, and swell height for the locations where whales were spotted. The environmental data from the sighting data is used as a guide when filling in the rest of the values along the trackline. When data, such as wind speed, swell height, or survey condition, is not explicitly given, matrices have been developed in collaboration with Dr. Leigh Torres to fill in the gaps in the data. These matrices and protocols for filling in the final conditions log are important tools for standardizing the environmental and condition data.
The final product for the survey conditions table is the output of all the code and matrices (Figure 5). The creation of this table will allow for accurate calculation of survey effort on each day, month, and year of the GRANITE project. This effort data is critical to evaluate trends in whale distribution, habitat use, and exposure to disturbances or threats.
Figure 5. A snippet of the completed 2019 season effort condition log.
The process of completing the table can be a very monotonous task, and there are several chances for the data to get misplaced or missed entirely. Attention to detail is a critical aspect of this project. Standardizing the GRANITE data is essential because it allows for consistency over the years and across platforms. In describing this aspect of my project, I mentioned three different computer programs using the same data. This behind-the-scenes work of creating and maintaining data standardization is critical for all projects, especially long-term research such as the GRANITE project.
Did you enjoy this blog? Want to learn more about marine life, research, and conservation? Subscribe to our blog and get a weekly message when we post a new blog. Just add your name and email into the subscribe box below.
By Alexa Kownacki, Ph.D. Student, OSU Department of Fisheries and Wildlife, Geospatial Ecology of Marine Megafauna Lab
Data wrangling, in my own loose definition, is the necessary combination of both data selection and data collection. Wrangling your data requires accessing then assessing your data. Data collection is just what it sounds like: gathering all data points necessary for your project. Data selection is the process of cleaning and trimming data for final analyses; it is a whole new bag of worms that requires decision-making and critical thinking. During this process of data wrangling, I discovered there are two major avenues to obtain data: 1) you collect it, which frequently requires an exorbitant amount of time in the field, in the lab, and/or behind a computer, or 2) other people have already collected it, and through collaboration you put it to a good use (often a different use then its initial intent). The latter approach may result in the collection of so much data that you must decide which data should be included to answer your hypotheses. This process of data wrangling is the hurdle I am facing at this moment. I feel like I am a data detective.
Data wrangling illustrated by members of the R-programming community. (Image source: R-bloggers.com)
My project focuses on assessing the health conditions of the two ecotypes of bottlenose dolphins between the waters off of Ensenada, Baja California, Mexico to San Francisco, California, USA between 1981-2015. During the government shutdown, much of my data was inaccessible, seeing as it was in possession of my collaborators at federal agencies. However, now that the shutdown is over, my data is flowing in, and my questions are piling up. I can now begin to look at where these animals have been sighted over the past decades, which ecotypes have higher contaminant levels in their blubber, which animals have higher stress levels and if these are related to geospatial location, where animals are more susceptible to human disturbance, if sex plays a role in stress or contaminant load levels, which environmental variables influence stress levels and contaminant levels, and more!
Alexa, alongside collaborators, photographing transiting bottlenose dolphins along the coastline near Santa Barbara, CA in 2015 as part of the data collection process. (Image source: Nick Kellar).
Over the last two weeks, I was emailed three separate Excel spreadsheets representing three datasets, that contain partially overlapping data. If Microsoft Access is foreign to you, I would compare this dilemma to a very confusing exam question of “matching the word with the definition”, except with the words being in different languages from the definitions. If you have used Microsoft Access databases, you probably know the system of querying and matching data in different databases. Well, imagine trying to do this with Excel spreadsheets because the databases are not linked. Now you can see why I need to take a data management course and start using platforms other than Excel to manage my data.
A visual interpretation of trying to combine datasets being like matching the English definition to the Spanish translation. (Image source: Enchanted Learning)
In the first dataset, there are 6,136 sightings of Common bottlenose dolphins (Tursiops truncatus) documented in my study area. Some years have no sightings, some years have fewer than 100 sightings, and other years have over 500 sightings. In another dataset, there are 398 bottlenose dolphin biopsy samples collected between the years of 1992-2016 in a genetics database that can provide the sex of the animal. The final dataset contains records of 774 bottlenose dolphin biopsy samples collected between 1993-2018 that could be tested for hormone and/or contaminant levels. Some of these samples have identification numbers that can be matched to the other dataset. Within these cross-reference matches there are conflicting data in terms of amount of tissue remaining for analyses. Sorting these conflicts out will involve more digging from my end and additional communication with collaborators: data wrangling at its best. Circling back to what I mentioned in the beginning of this post, this data was collected by other people over decades and the collection methods were not standardized for my project. I benefit from years of data collection by other scientists and I am grateful for all of their hard work. However, now my hard work begins.
The cutest part of data wrangling: finding adorable images of bottlenose dolphins, photographed during a coastal survey. (Image source: Alexa Kownacki).
There is also a large amount of data that I downloaded from federally-maintained websites. For example, dolphin sighting data from research cruises are available for public access from the OBIS (Ocean Biogeographic Information System) Sea Map website. It boasts 5,927,551 records from 1,096 data sets containing information on 711 species with the help of 410 collaborators. This website is incredible as it allows you to search through different data criteria and then download the data in a variety of formats and contains an interactive map of the data. You can explore this at your leisure, but I want to point out the sheer amount of data. In my case, the OBIS Sea Map website is only one major platform that contains many sources of data that has already been collected, not specifically for me or my project, but will be utilized. As a follow-up to using data collected by other scientists, it is critical to give credit where credit is due. One of the benefits of using this website, is there is information about how to properly credit the collaborators when downloading data. See below for an example:
Example citation for a dataset (Dataset ID: 1201):
Lockhart, G.G., DiGiovanni Jr., R.A., DePerte, A.M. 2014. Virginia and Maryland Sea Turtle Research and Conservation Initiative Aerial Survey Sightings, May 2011 through July 2013. Downloaded from OBIS-SEAMAP (http://seamap.env.duke.edu/dataset/1201) on xxxx-xx-xx.
Another federally-maintained data source that boasts more data than I can quantify is the well-known ERDDAP website. After a few Google searches, I finally discovered that the acronym stands for Environmental Research Division’s Data Access Program. Essentially, this the holy grail of environmental data for marine scientists. I have downloaded so much data from this website that Excel cannot open the csv files. Here is yet another reason why young scientists, like myself, need to transition out of using Excel and into data management systems that are developed to handle large-scale datasets. Everything from daily sea surface temperatures collected on every, one-degree of latitude and longitude line from 1981-2015 over my entire study site to Ekman transport levels taken every six hours on every longitudinal degree line over my study area. I will add some environmental variables in species distribution models to see which account for the largest amount of variability in my data. The next step in data selection begins with statistics. It is important to find if there are highly correlated environmental factors prior to modeling data. Learn more about fitting cetacean data to models here.
The ERDAPP website combined all of the average Sea Surface Temperatures collected daily from 1981-2018 over my study site into a graphical display of monthly composites. (Image Source: ERDDAP)
As you can imagine, this amount of data from many sources and collaborators is equal parts daunting and exhilarating. Before I even begin the process of determining the spatial and temporal spread of dolphin sightings data, I have to identify which data points have sex identified from either hormone levels or genetics, which data points have contaminants levels already quantified, which samples still have tissue available for additional testing, and so on. Once I have cleaned up the datasets, I will import the data into the R programming package. Then I can visualize my data in plots, charts, and graphs; this will help me identify outliers and potential challenges with my data, and, hopefully, start to see answers to my focal questions. Only then, can I dive into the deep and exciting waters of species distribution modeling and more advanced statistical analyses. This is data wrangling and I am the data detective.
What people may think a ‘data detective’ looks like, when, in reality, it is a person sitting at a computer. (Image source: Elder Research)
Like the well-known phrase, “With great power comes great responsibility”, I believe that with great data, comes great responsibility, because data is power. It is up to me as the scientist to decide which data is most powerful at answering my questions.
Data is information. Information is knowledge. Knowledge is power. (Image source: thedatachick.com)











{kind=link}