Part of what makes being a graduate student so exciting is the way that learning can flip the world around: you learn a new framework or method, and suddenly everything looks a little different. I am experiencing this fabulous phenomenon lately as I learn to collect and process active acoustic data, which can reveal the distribution and biomass of animals in the ocean – including those favored by foraging whales off of Oregon, like the tiny shrimp-like krill.
We know that whales seek out the dense, energy-rich swarms that krill form, and that knowing where to expect krill can give us a leg up in anticipating whale distributions. Project OPAL (Overlap Predictions About Large whales) seeks to model and provide robust predictions of whale distributions off the coast of Oregon, so that managers can make spatially discrete decisions about potential fishery closures, minimizing burdens to fishermen while also maximizing protection of whales. We hope that including prey in our ecosystem models will help this effort, and working on this aim is one of the big tasks of my PhD.
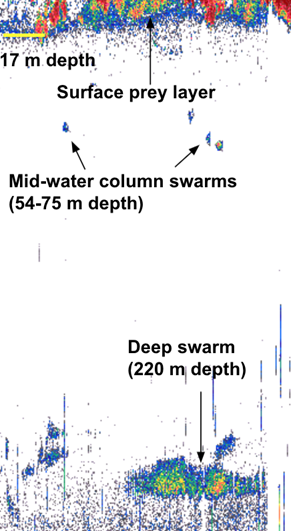
So, how do we know where to expect krill to be off the coast of Oregon? Acoustic tools give us the opportunity to flip the world upside down: we use a tool called an echosounder to eavesdrop on the ocean, yielding visual outputs like the ones below that let us “see” and interpret sound.
Echograms like these reveal features in the ocean that scatter “pings” of sound, and interpreting these signals can show life in the water column.
This is how it works. The echosounder emits pulses of sound at a known frequency, and then it listens for their return after it bounces of the sea floor or things in the water column. Based on sound experiments in the laboratory, we know to expect our krill species, Euphausia pacifica and Thysanoessa spinifera, to return those echoes at a characteristic decibel level. By constantly “pinging” the water column with this sound, we can record a continuous soundscape along the cruise track of a vessel, and analyze it to identify the animals and features recorded.
I had the opportunity to use an echosounder for the first time recently, on the first HALO cruise. We deployed the echosounder soon after sunrise, 65 miles offshore from Newport. After a little fiddling and troubleshooting, I was thrilled to start “listening” to the water; I was able to see the frothy noise at its surface, the contours of the seafloor, and the pixelated patches that indicate prey in between. Although it’s difficult to definitively identify animals only based on the raw output, we saw swarms that looked like our beloved krill, and other aggregations that suggested hake. Sometimes, at the same time that the team of visual observers on the flying bridge of the vessel sighted whales, I also saw potential prey on the echogram.
I spent much of the HALO cruise monitoring incoming data from the transducer on the SIMRAD EK60. Photo: Marissa Garcia.
I’m excited to keep collecting these data, and grateful that I can also access acoustic data collected by others. Many research vessels use echosounders while they are underway, including the NOAA Ship Bell M. Shimada, which conducts cruises in the Northern California Current several times a year. Starting in 2018, GEMM Lab members have joined these cruises to conduct marine mammal surveys.
This awesome pairing of data types means that we can analyze the prey that was available at the time of marine mammal sightings. I’ve been starting to process acoustic data from past Northern California Current cruises, eavesdropping on the preyscape in places that were jam-packed with whales, such as this echogram from the September 2020 cruise, below.
An echogram from the September 2020 NCC cruise shows a great deal of prey at different depths.
Like a lot of science, listening to animals in the sea comes down to occasional bursts of fieldwork followed by a lot of clicking on a computer screen during data analysis. This analysis can be some pretty fun clicking, though – it’s amazing to watch the echogram unfurl, revealing the preyscape in a swath of ocean. I’m excited to keep clicking, and learn what it can tell us about whale distributions off of Oregon.
Solène Derville, Entropie Lab, French National Institute for Sustainable Development (IRD – UMR Entropie), Nouméa, New Caledonia
Ph.D. student under the co-supervision of Dr. Leigh Torres
Species Distribution Models (SDM), also referred to as ecological niche models, may be defined as “a model that relates species distribution data (occurrence or abundance at known locations) with information on the environmental and/or spatial characteristics of those locations” (Elith & Leathwick, 2009). In the last couple decades, SDMs have become an indispensable part of the ecologists’ and conservationists’ toolbox. What scientist has not dreamed of being able to summarize a species’ environmental requirements and predict where and when it will occur, all in one tiny statistical model? It sounds like magic… but the short acronym “SDM” is the pretty front window of an intricate and gigantic research field that may extend way beyond the skills of a typical ecologist (even so for a graduate student like myself).
As part of my PhD thesis about the spatial ecology of humpback whales in New Caledonia, South Pacific, I was planning on producing a model to predict their distribution in the region and help spatial planning within the Natural Park of the Coral Sea. An innocent and seemingly perfectly feasible plan for a second year PhD student. To conduct this task, I had at my disposal more than 1,000 sightings recorded during dedicated surveys at sea conducted over 14 years. These numbers seem quite sufficient, considering the rarity of cetaceans and the technical challenges of studying them at sea. And there was more! The NGO Opération Cétacés also recorded over 600 sightings reported by the general public in the same time period and deployed more than 40 satellite tracking tags to follow individual whale movements. In a field where it is so hard to acquire data, it felt like I had to use it all, though I was not sure how to combine all these types of data, with their respective biases, scales and assumptions.
One important thing about SDM to remember: it is like a cracker section in a US grocery shop, there is sooooo much choice! As I reviewed the possibilities and tested various modeling approaches on my data I realized that this study might be a good opportunity to contribute to the SDM field, by conducting a comparison of various algorithms using cetacean occurrence data from multiple sources. The results of this work was just published in Diversity and Distributions:
Derville S, Torres LG, Iovan C, Garrigue C. (2018) Finding the right fit: Comparative cetacean distribution models using multiple data sources and statistical approaches. Divers Distrib. 2018;00:1–17. https://doi. org/10.1111/ddi.12782
There are simply too many! Anonymous grocery shops, Corvallis, OR Credit: Dawn Barlow
If you are a new-comer to the SDM world, and specifically its application to the marine environment, I hope you find this interesting. If you are a seasoned SDM user, I would be very grateful to read your thoughts in the comment section! Feel free to disagree!
So what is the take-home message from this work?
There is no such thing as a “best model”; it all depends on what you want your model to be good at (the descriptive vs predictive dichotomy), and what criteria you use to define the quality of your models.
The predictive vs descriptive goal of the model: This is a tricky choice to make, yet it should be clearly identified upfront. Most times, I feel like we want our models to be decently good at both tasks… It is a risky approach to blindly follow the predictions of a complex model without questioning the meaning of the ecological relationships it fitted. On the other hand, conservation applications of models often require the production of predicted maps of species’ probability of presence or habitat suitability.
The criteria for model selection: How could we imagine that the complexity of animal behavior could be summarized in a single metric, such as the famous Akaike Information criterion (AIC) or the Area under the ROC Curve (AUC)? My study, and that of others (e.g. Elith & Graham H., 2009), emphasize the importance of looking at multiple aspects of model outputs: raw performance through various evaluation metrics (e.g. see AUCdiff; (Warren & Seifert, 2010), contribution of the variables to the model, shape of the fitted relationships through Partial Dependence Plots (PDP, Friedman, 2001), and maps of predicted habitat suitability and associated error. Spread all these lines of evidence in front of you, summarize all the metrics, add a touch of critical ecological thinking to decide on the best approach for your modeling question, and Abracadabra! You end up a bit lost in a pile of folders… But at least you assessed the quality of your work from every angle!
Cetacean SDMs often serve a conservation goal. Hence, their capacity to predict to areas / times that were not recorded in the data (which is often scarce) is paramount. This extrapolation performance may be restricted when the model relationships are overfitted, which is when you made your model fit the data so closely that you are unknowingly modeling noise rather than a real trend. Using cross-validation is a good method to prevent overfitting from happening (for a thorough review: Roberts et al., 2017). Also, my study underlines that certain algorithms inherently have a tendency to overfit. We found that Generalized Additive Models and MAXENT provided a valuable complexity trade-off to promote the best predictive performance, while minimizing overfitting. In the case of GAMs, I would like to point out the excellent documentation that exist on their use (Wood, 2017), and specifically their application to cetacean spatial ecology (Mannocci, Roberts, Miller, & Halpin, 2017; Miller, Burt, Rexstad, & Thomas, 2013; Redfern et al., 2017).
Citizen science is a promising tool to describe cetacean habitat. Indeed, we found that models of habitat suitability based on citizen science largely converged with those based on our research surveys. The main issue encountered when modeling this type of data is the absence of “effort”. Basically, we know where people observed whales, but we do not know where they haven’t… or at least not with the accuracy obtained from research survey data. However, with some information about our citizen scientists and a little deduction, there is actually a lot you can infer about opportunistic data. For instance, in New Caledonia most of the sightings were reported by professional whale-watching operators or by the general public during fishing/diving/boating day trips. Hence, citizen scientists rarely stray far from harbors and spend most of their time in the sheltered waters of the New Caledonian lagoon. This reasoning provides the sort of information that we integrated in our modeling approach to account for spatial sampling bias of citizen science data and improve the model’s predictive performance.
Many more technical aspects of SDM are brushed over in this paper (for detailed and annotated R codes of the modeling approaches, see supplementary information of our paper). There are a few that are not central to the paper, but that I think are worth sharing:
Collinearity of predictors: Have you ever found that the significance of your predictors completely changed every time you removed a variable? I have progressively come to discover how unstable a model can be because of predictor collinearity (and the uneasy feeling that comes with it …). My new motto is to ALWAYS check cross-correlation between my predictors, and do it THOROUGHLY. A few aspects that may make a big difference in the estimation of collinearity patterns are to: (1) calculate Pearson vs Spearman coefficients, (2) check correlations between the values recorded at the presence points vs over the whole study area, and (3) assess the correlations between raw environmental variables vs between transformed variables (log-transformed, etc). Though selecting variables with Pearson coefficients < 0.7 is usually a good rule (Dormann et al., 2013), I would worry of anything above 0.5, or at least keep it in mind during model interpretation.
Cross-validation: If removing 10% of my dataset greatly impacts the model results, I feel like cross-validation is critical. The concept is based on a simple assumption, if I had sampled a given population/phenomenon/system slightly differently, would I have come to the same conclusion? Cross-validation comes in many different methods, but the basic concept is to run the same model several times (number of times may depend on the size of your data set, hierarchical structure of your data, computation power of your computer, etc.) over different chunks of your data. Model performance metrics (e.g., AUC) and outputs (e.g., partial dependence plots) are than summarized on the many runs, using mean/median and standard deviation/quantiles. It is up to you how to pick these chunks, but before doing this at random I highly recommend reading Roberts et al. (2017).
The evil of the R2: I am probably not the first student to feel like what I have learned in my statistical classes at school is in practice, at best, not very useful, and at worst, dangerously misleading. Of course, I do understand that we must start somewhere, and that learning the basics of inferential statistics is a necessary step to, one day, be able to answer your one research questions. Yet, I feel like I have been carrying the “weight of the R2” for far too long before actually realizing that this metric of model performance (R2 among others) is simply not enough to trust my results. You might think that your model is robust because among the 1000 alternative models you tested, it is the one with the “best” performance (deviance explained, AIC, you name it), but the model with the best R2 will not always be the most ecologically meaningful one, or the most practical for spatial management perspectives. Overfitting is like a sword of Damocles hanging over you every time you create a statistical model All together, I sometimes trust my supervisor’s expertise and my own judgment more than an R2.
Source: internet
A few good websites/presentations that have helped me through my SDM journey:
Dormann, C. F., Elith, J., Bacher, S., Buchmann, C., Carl, G., Carré, G., … Lautenbach, S. (2013). Collinearity: A review of methods to deal with it and a simulation study evaluating their performance. Ecography, 36(1), 027–046. https://doi.org/10.1111/j.1600-0587.2012.07348.x
Elith, J., & Graham H., C. (2009). Do they? How do they? WHY do they differ? On finding reasons for differing performances of species distribution models . Ecography, 32(Table 1), 66–77. https://doi.org/10.1111/j.1600-0587.2008.05505.x
Elith, J., & Leathwick, J. R. (2009). Species Distribution Models: Ecological Explanation and Prediction Across Space and Time. Annual Review of Ecology, Evolution, and Systematics, 40(1), 677–697. https://doi.org/10.1146/annurev.ecolsys.110308.120159
Friedman, J. H. (2001). Greedy Function Approximation: A gradient boosting machine. The Annals of Statistics, 29(5), 1189–1232. Retrieved from http://www.jstor.org/stable/2699986
Mannocci, L., Roberts, J. J., Miller, D. L., & Halpin, P. N. (2017). Extrapolating cetacean densities to quantitatively assess human impacts on populations in the high seas. Conservation Biology, 31(3), 601–614. https://doi.org/10.1111/cobi.12856.This
Miller, D. L., Burt, M. L., Rexstad, E. A., & Thomas, L. (2013). Spatial models for distance sampling data: Recent developments and future directions. Methods in Ecology and Evolution, 4(11), 1001–1010. https://doi.org/10.1111/2041-210X.12105
Redfern, J. V., Moore, T. J., Fiedler, P. C., de Vos, A., Brownell, R. L., Forney, K. A., … Ballance, L. T. (2017). Predicting cetacean distributions in data-poor marine ecosystems. Diversity and Distributions, 23(4), 394–408. https://doi.org/10.1111/ddi.12537
Roberts, D. R., Bahn, V., Ciuti, S., Boyce, M. S., Elith, J., Guillera-Arroita, G., … Dormann, C. F. (2017). Cross-validation strategies for data with temporal, spatial, hierarchical or phylogenetic structure. Ecography, 0, 1–17. https://doi.org/10.1111/ecog.02881
Warren, D. L., & Seifert, S. N. (2010). Ecological niche modeling in Maxent: the importance of model complexity and the performance of model selection criteria. Ecological Applications, 21(2), 335–342. https://doi.org/10.1890/10-1171.1
Wood, S. N. (2017). Generalized additive models: an introduction with R (second edi). CRC press.