By Dawn Barlow, PhD student, OSU Department of Fisheries and Wildlife, Geospatial Ecology of Marine Megafauna Lab
Recently, I had the opportunity to attend the International Statistical Ecology Conference (ISEC), a biennial meeting of researchers at the interface of ecology and statistics. I am a marine ecologist, fascinated by the interactions between animals and the dynamic ocean environment they inhabit. If you had asked me five years ago whether I thought I would ever consider myself a statistician or a computer programmer, my answer would certainly have been “no”. Now, I find myself studying the ecology of blue whales in New Zealand using a variety of data streams and methodologies, but a central theme for my dissertation is species distribution modeling. Species distribution models (SDMs) are mathematical algorithms that correlate observations of a species with environmental conditions at their observed locations to gain ecological insight and predict spatial distributions of the species (Fig. 1; Elith and Leathwick 2009). I still can’t say I would identify as a statistician, but I have a growing appreciation for the role of statistics to gain inference in ecology.
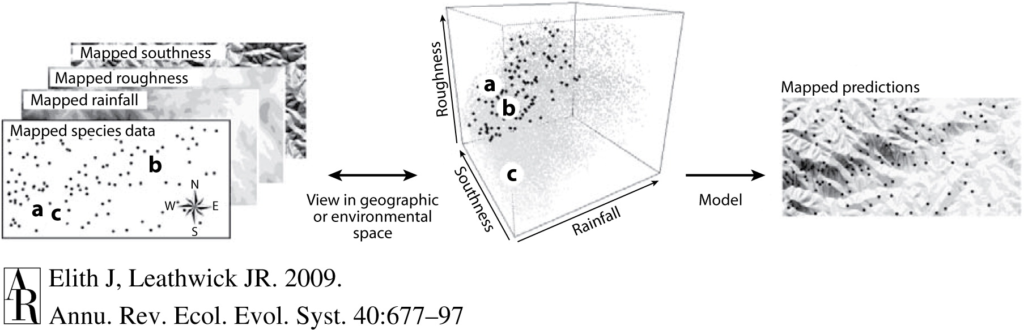
Before I continue, let’s take a look at just a few definitions from Merriam-Webster’s dictionary:
Statistics: a branch of mathematics dealing with the collection, analysis, interpretation, and presentation of masses of numerical data
Ecology: a branch of science concerned with the interrelationship of organisms and their environments
Inference: a conclusion or opinion that is formed because of known facts or evidence
Ecological data are notoriously noisy, messy, and complex. Statistical tests are meant to help us understand whether a pattern in the data is different from what we would expect through random chance. When we study how organisms interact with one another and their environment, it is impossible to completely capture all elements of the ecosystem. Therefore, ecology is a field ripe with challenges for statisticians. How do we quantify a meaningful biological signal amidst all the noise? How can we gain inference from ecological data to enhance knowledge, and how can we use that knowledge to make informed predictions? Marine mammals are notoriously difficult to study. They inhabit an environment that is relatively inaccessible and inhospitable to humans, they occur in low numbers, they are highly mobile, and they are rarely visible. All ecological data are difficult and noisy and riddled with small sample sizes, but counting trees presents fewer logistical challenges than counting moving whales in an ever-changing open-ocean setting. Therefore, new methodologies in areas like species distribution modeling are often developed using large, terrestrial datasets and eventually migrate to applications in the marine environment (Robinson et al. 2011).
Many presentations I attended at the conference were geared toward moving beyond correlative SDMs. SDMs were developed to correlate species occurrence patterns with features of the environment they inhabit (e.g. temperature, precipitation, terrain, etc.). However, those relationships do not actually explain the underlying mechanism of why a species is more likely to occur in one environment compared to another. Therefore, ecological statisticians are now using additional information and modeling approaches within SDMs to incorporate information such as species co-occurrence patterns, population demographic information, and physiological constraints. Building SDMs to include such process-explicit information allows us to make steps toward understanding not just when and where a species occurs, but why.
Machine learning is an area that continues to advance and open doors to new applications in ecology. Machine learning approaches differ fundamentally from classical statistics. In statistics, we formulate a hypothesis, select the appropriate model to test that hypothesis (for example, linear regression), then test how well the data fit the model (“Is the relationship linear?”), and test the strength of that inference (“Is the linear pattern different from what we would expect due to random chance?”). Machine learning, on the other hand, does not use a predetermined notion of relationships between variables. Rather, it tries to create an algorithm that fits the patterns in the data. Statistics asks how well the data fit a model, and machine learning asks how well a model fits the data.
Machine learning approaches allow for very complex relationships to be included in models and can be excellent for making predictions. However, sometimes the relationships fitted by a machine learning algorithm are so complex that it is not possible to infer any ecological meaning from them. As one ISEC presenter put it, in machine learning “the computer learns but the scientist does not”. The most important thing when selecting your methodology is to remember your question and your goal. Do you want to understand the mechanism of why an animal is where it is? Or do you not need to understand the driver, but rather want to make the best predictions of where an animal will be? In my case, the answer to that question differs from one of my PhD chapters to the next. We want to understand the functional relationships between oceanography, krill availability, and blue whale distribution (Barlow et al. 2020), and subsequently we want to develop forecasting models that can reliably predict blue whale distribution to inform conservation efforts (Fig. 2).

ISEC was an excellent opportunity for me to break out of my usual marine mammal-centered bubble and get a taste of what is happening on the leading edge of statistical ecology. I learned about the latest approaches and innovations in species distribution modeling, and in the process I also learned about trees, koalas, birds, and many other organisms from around the world. A fun bonus of attending a methods-focused conference is learning about completely new study species and systems. There are many ways of approaching an ecological question, gaining inference, and making predictions. I look forward to incorporating the knowledge I gained through ISEC into my own research, both in my doctoral work and in applications of new methods to future research projects.

References
Barlow, D.R., Bernard, K.S., Escobar-Flores, P., Palacios, D.M., and Torres, L.G. 2020. Links in the trophic chain: Modeling functional relationships between in situ oceanography, krill, and blue whale distribution under different oceanographic regimes. Mar. Ecol. Prog. Ser. doi:https://doi.org/10.3354/meps13339.
Elith, J., and Leathwick, J.R. 2009. Species Distribution Models: Ecological Explanation and Prediction Across Space and Time. Annu. Rev. Ecol. Evol. Syst. 40(1): 677–697. doi:10.1146/annurev.ecolsys.110308.120159.
Robinson, L.M., Elith, J., Hobday, A.J., Pearson, R.G., Kendall, B.E., Possingham, H.P., and Richardson, A.J. 2011. Pushing the limits in marine species distribution modelling: Lessons from the land present challenges and opportunities. doi:10.1111/j.1466-8238.2010.00636.x.