This week we have Andrea Domen, a MS student in Food Science and Technology co-advised by Dr. Joy Waite-Cusic and Dr. Jovana Kovacevic, joining us to discuss her research investigating some mischievous pathogenic microbes. Much like an unwelcome dinner guest, food-bourne pathogens can stick around for far longer than you think. Andrea seeks to uncover the mechanisms that allow for Listeria monocytogenes, a ubiquitous pathogen found in dirt that loves cheese (who doesn’t?), to persist in dairy processing facilities.
Listeria hysteria
Way back in the early 2000s, there were two listeriosis outbreaks that were linked to cheese. Because of these two outbreaks, the British Columbia Centre for Disease Control conducted a sampling program over the course of a decade. From this program, 88 isolates of L. monocytogenes from five different facilities were recovered. Within this set of isolates, 63 were from one facility which is now (perhaps unsurprisingly) shut down. Those 63 microbes were essentially clones of each other, which means this one lineage of microbes seemed to carry something that allowed them to survive for multiple years. So how did that lineage of Listeria survive? Turns out, like a 1990’s Reebok, they pump it. Listeria uses a protein in its cell membrane called an efflux pump to remove harmful chemicals like sanitizers, antibiotics, and heavy metals from the cell. Essentially, when the cell absorbs something that is too spicy – it’ll yeet it back out.
gif of an efflux pump
Don’t cry over contaminated milk
The idea that food borne pathogens are evolving to withstand processing environments is alarming, but fret not, the results of Andrea’s research are a first step to avoiding the creation of these super microbes in the first place. Instead, it can serve as a warning story for dairy production facilities about what can happen when L. monocytogenes contamination isn’t properly handled. In healthcare, it’s not uncommon to treat a microbial pathogen with multiple medications – as becoming resistant to several treatments is harder for the microbe than becoming resistant to just one. We are also able to apply this treatment method to sanitizing food production facilities by combining different sanitizers – but that is best left up to the chemists to avoid accidentally making an explosion or lethal gas.
Andrea Domen
To hear more about how Listeria can survive better than Destiny’s Child be sure to listen live on Sunday, May 7th at 7PM on 88.7FM, or download the podcast.
This week we have a Fisheries and Wildlife Master’s student and ODFW employee, Gabriella Brill, joining us to discuss her research investigating the impact of dams on the movement and reproduction habits of the White Sturgeon here in Oregon. Much like humans, these fish can live up to 100 years and can take 25 years to fully mature. But the similarities stop there, as they can also grow up to 10 ft long, haven’t evolved much in 200 million years, and can lay millions of eggs at a time (makes the Duggar family’s 19 Kids and Counting not seem so bad).
Despite being able to lay millions of eggs at a time, the White Sturgeon will only do so if the conditions are right. This fish Goldilocks’ its way through the river systems, looking for a river bed that’s just right. If it doesn’t like what it sees, the fish can just choose not to lay the eggs and will wait for another year. When the fish don’t find places they want to lay their eggs, it can cause drastic changes to the overall population size. This can be a problem for people whose lives are intertwined with these fish: such as fishermen and local Tribal Nations (and graduate students).
The white sturgeon was once a prolific fish in the Columbia River and holds ceremonial significance to local Tribal Nations, however, post-colonialization a fishery was established in 1888 that collapsed the population just four years later in 1892. Due to the long lifespan of these fish, the effects of that fishery are something today’s populations have still not fully recovered from.
White Sturgeon
Can you hear me now
Gabriella uses sound transmitters to track the white sturgeon’s movements. Essentially, the fish get a small sound-emitting implant that is picked up by a series of receivers – as long the receivers don’t get washed away by a strong current. By monitoring the fish’s journey through the river systems, she can then determine if the man-made dams are impacting their ability to find a desirable place to lay eggs.
Journey to researching a sturgeon’s journey
Gabriella always gravitated towards ecology due to the ways it blends many different sciences and ideas – and Fish are a great system for studying ecology. She started with studying Salmon in undergrad which eventually led to a position with the ODFW. Working with the ODFW inspired her to get a Master’s degree so that she could gain the necessary experience and credentials to be a more effective advocate for changes in conservation efforts that are being made. One way to get clout in the fish world: study a highly picky fish with a long life cycle. Challenge accepted.
Gabriella Brill holding a smaller sturgeon while on a boat.
To hear more about these finicky fish be sure to listen live on Sunday February 26th at 7PM on 88.7FM, or download the podcast.
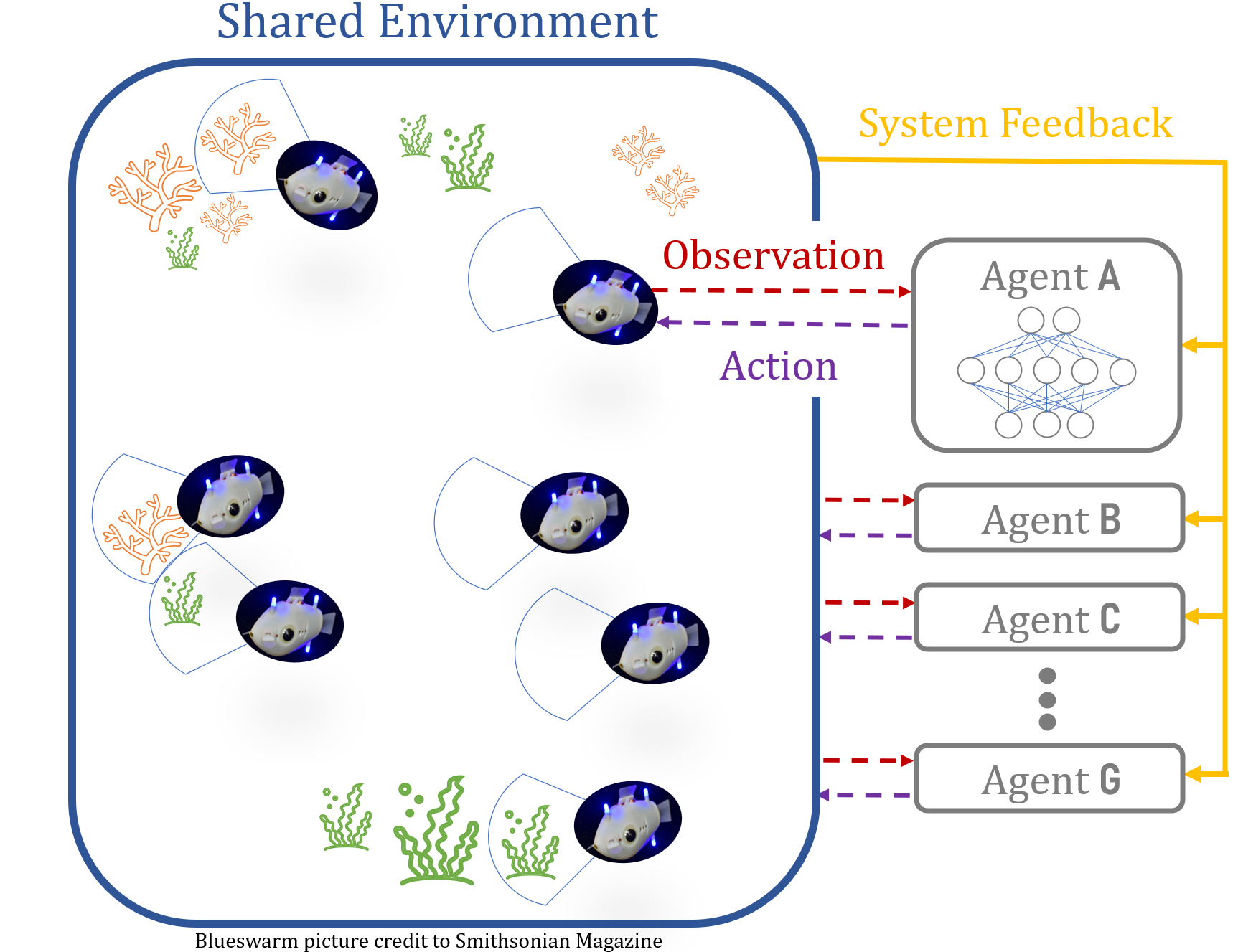
This week we have a robotics PhD student, Everardo Gonzalez, joining us to discuss his research on coordinating robots with artificial intelligence (AI). That doesn’t mean he dresses them up in matching bow ties (sadly), but instead he works on how to get a large collective of robots, also called a swarm, to work collectively towards a shared goal.
Why should we care about swarming robots?
Aside from the potential for an apocalyptic robot world domination, there are actually many applications for this technology. Some are just as terrifying. It could be applied to fully automated warfare – reducing accountability when no one is to blame for pulling the trigger (literally).
However, it could also be used to coordinate robots used in healthcare and with organizing fleets of autonomous vehicles, potentially making our lives, and our streets, safer. In the case of the fish-inspired Blue Bots, this kind of coordinated robot system can also help us gather information about our oceans as we try to resolve climate change.
Depiction of how the fish-inspired Blue Bots can observe their surroundings in a shared aquatic space, then send that information and receive feedback from the computer system. Driving the Blue Bots’ behavior is a network model, as depicted in the Agent A square.
#Influencer
Having a group of intelligent robots behaving intelligently sounds like it’s a problem of quantity, however, it’s not that simple. These bots can also suffer from there being “too many cooks in the kitchen”, and, if all bots in the swarm are intelligent, they can start to hinder each other’s progress. Instead, the swarm needs both a few leader bots, that are intelligent and capable of learning and trying new things, along with follower bots, which can learn from their leader. Essentially, the bots play a game of “Follow the Leaders”.
All robots receive feedback with respect to a shared objective, which is typical of AI training and allow the bots to infer which behaviors are effective. In this case, the leaders will get additional feedback on how well they are influencing their followers.
Unlike social media, one influencer with too many followers is a bad thing – and the bots can become ineffective. There’s a famous social experiment in which actors in a busy New York City street stopped to stare at a window to determine if strangers would do the same. If there are not enough actors staring at the window, strangers are unlikely to respond. But as the number of actors increases, the likeness of a stranger stopping to look will also increase. The bot swarms also have an optimal number of leaders required to have the largest influence on their followers. Perhaps we’re much more like robots than the Turing test would have us believe.
Dot to dot
We’re a long way from intelligent robot swarms, though, as Everardo is using simplified 2D particle simulations to begin to tackle this problem. In this case the particles replace the robots, and are essentially just dots (rodots?) in a shared environment that only has two dimensions. The objectives or points of interest for these dot bots are more dots! Despite these simplifications, translating system feedback into a performance review for the leaders is still a challenging problem to solve computationally. Everardo starts by asking the question “what if the leader had not been there”, but then you have to ask “what if the followers that followed that leader did something else?” and then you’ve opened a can of worms reminiscent of Smash Mouth where the “what if”’s start coming and they don’t stop coming.
Everardo Gonzalez
What if you wanted to know more about swarming robots? Be sure to listen live on Sunday February 26th at 7PM on 88.7FM, or download the podcast if you missed it. To learn a bit more about Everardo’s work with swarms and all things robotics, check out his portfolio at everardog.github.io.
This week we have a MS (but soon to be PhD) student from the department of Fisheries and Wildlife, Charles Nye, joining us to discuss their work examining the dietary and environmental DNA of whales. So that begs the question – how exactly does an environment, or a diet, have DNA? Essentially, the DNA of many organisms can be isolated from samples of ocean water near the whales, or in the case of dietary DNA, can be taken from the whales’ fecal matter – that’s right, there’s a lot more you can get from poop than just an unpleasant smell.
Why should we care about what whales eat?
As the climate changes, so too does the composition of creatures and plants in the oceans. Examining environmental DNA gives Charles information on the nearby ecological community – which in turn gives information about what is available for the whale to eat plus what other creatures they may be in resource competition with. He is working to identify the various environmental DNA present to assist with conservation efforts for the right whale near Cape Cod – a whale that they hold as dear to their hearts on the East Coast as the folks of Depoe Bay hold the grey whale to theirs.
By digging into the whale poop to extract dietary DNA, Charles can look into how the whales’ diets shift over seasonal and yearly intervals – and he is doing precisely that with the West Coast grey whales. These dietary shifts may be important for conservation purposes, and may also be applied to studying behavior. For example, by looking at whether or not there are sex differences in diet and asking the ever-important question: do whales also experience bizarre pregnancy cravings?
Scuba diving underwater.
How does someone even get to study whales?
Like many careers, it starts with an identity crisis. Charles originally thought they’d go into scientific illustration, but quickly realized that they didn’t want to turn a hobby he enjoyed into a job with deadlines and dread. A fortunate conversation with his ecology professor during undergrad inspired him to join a research lab studying intertidal species’ genetics – and eventually become a technician at the Monterey Bay Aquarium Research Institute.
After a while, simply doing the experiments was not enough and they wanted to be able to ask his own questions like “does all the algae found in a gray whale’s stomach indicate they may actually be omnivores, unlike their carnivorous whale peers?” (mmm, shrimp).
Turns out, in order to study whales all you have to do is start small – tiny turban snail small.
Working in the lab.
Excited for more whale tales? Us too. Be sure to listen live on Sunday, February 5th at 7PM on 88.7FM, or download the podcast if you missed it. Want to stay up to date with the world of whales and art? Follow Charles @thepaintpaddock on Twitter/Instagram for his art or @cnyescienceguy on Twitter for his marine biology musings.
Machines take me by surprise with great frequency. – Alan Turing
This week we have a PhD student from the College of Engineering and advised by Dr. Maude David in Microbiology, Nima Azbijari, to discuss how he uses machine learning to better understand biology. Before we dig in to the research, let’s dig into what exactly machine learning is, and how it differs from artificial intelligence (AI). Both AI and machine learning learn patterns from data they are fed, but the difference is that AI is typically developed to be interacted with and make decisions in real time. If you’ve ever lost a game of chess to a computer, that was AI playing against you. But don’t worry, even the world’s champion at an even more complex game, Go, was beaten by AI. AI utilizes machine learning, but not all machine learning is AI. Kind of like how a square is a rectangle, but not all rectangles are squares. The goal of machine learning is to use data to improve at tasks using data it is fed.
So how exactly does a machine, one of the least biological things on this planet, help us understand biology?
Ten years ago it was big news that a computer was able to recognize images of cats, but now photo recognition is quite common. Similarly, Nima uses machine learning with large sets of genomic (genes/DNA), proteomic (proteins), and even gut microbiomic data (symbiotic microbes in the digestive track) to then see if the computer can predict varying patient outcomes. By using computational power, larger data sets and the relationships between the varying kinds of data can be analyzed more quickly. This is great for both understanding the biological world in which we live, and also for the potential future of patient care.
How exactly do you teach an old machine a new trick?
First, it’s important to note that he’s using a machine, not magic, and it can be massively time consuming (even for a computer) to do any kind of analysis on every element of a massive set. Potentially millions of computations, or even more. So to isolate only the data that matters, Nima uses graph neural networks to extrapolate the important pieces. Imagine if you had a data set about your home, and you counted both the number of windows and the number of blinds and found that they were the same. Then you might conclude that you only need to count windows, and that counting blinds doesn’t tell you anything new. The same idea works with reducing data into only the components that add meaning.
The phrase ‘neural network’ can invoke imagery of a massive computer-brain made of wires, but what does this neural network look like, exactly? The 1999 movie The Matrix borrowed its name from a mathematical object which contains columns and rows of data, much like the iconic green columns of data from the movie posters. These matrices are useful for storing and computing data sets since they can be arranged much like an excel sheet, with columns for each patient and rows for each type of recorded data. He (or the computer?) can then work with that matrix to develop this neural network graph. Then, the neural network determines which data is relevant and can also illustrate connections between the different pieces of data. Much like how you might be connected to friends, coworkers, and family on a social network, except in this case, each profile is a compound or molecule and the connections can be any kind of relationship, such as a common reaction between the pair. However, unlike a social network, no one cares how many degrees from Kevin Bacon they are. The goal here isn’t to connect one molecule to another but to instead identify unknown relationships. Perhaps that makes it more like 23 and Me than Facebook.
TLDR
Nima is using machine learning to discover previously unknown relationships between various kinds of human biological data such as genes and the gut microbiome. Now, that’s a machine you don’t need to rage against.
Excited to learn more about machine learning? Us too. Be sure to listen live on Sunday November 13th at 7PM on 88.7FM, or download the podcast if you missed it. And if you want to stay up to date on Nima’s research, you can follow them on Twitter.
This week we have Colin Shea-Blymyer, a PhD student from OSU’s new AI program in the departments of Electrical Engineering and Computer Science, joining us to talk about coding computer ethics. Advancements in artificial intelligence (AI) are exploding, and while many of us are excited for a world where our Roomba’s evolve into Rosie’s (á la The Jetsons) – some of these technological advancements require grappling with ethical dilemmas. Determining how these AI technologies should make their decisions is a question that simply can’t be answered, and is best left to be debated by the spirits of John Stewart Mill and Immanual Kant. However, as a society, we are in dire need of a way to communicate ethics in a language that machines can understand – and this is exactly what Colin is developing.
Making An Impact: why coding computer ethics matters
A lot of AI is developed through machine learning – a process where software becomes more accurate without being explicitly told to do so. One example of this is through image recognition softwares. By feeding these algorithms with more and more photos of a cat – it will get better at recognizing what is and isn’t a cat. However, these algorithms are not perfect. How will the program treat a stuffed animal of a cat? How will it categorize the image of a cat on a t-shirt? When the stakes are low, like in image recognition, these errors may not matter as much. But for some technology being correct most of the time isn’t sufficient. We would simply not accept a pace-maker that operates correctly most of the time, or a plane that doesn’t crash into the mountains with just 95% certainty. Technologies that require a higher precision for safety also require a different approach to developing that software, and many applications of AI will require high safety standards – such as with self-driving cars or nursing robots. This means society is in need of a language to communicate with the AI in a way that it can understand ethics precisely, and with 100% accuracy. The Trolley Problemis a famous ethical dilemma that asks: if you are driving a trolley and see that it is going to hit and kill five pedestrians, but you could pull a lever to reroute the trolley to instead hit and kill one pedestrian – would you do it? While it seems obvious that we want our self-driving cars to not hit pedestrians, what is less obvious is what the car should do when it doesn’t have a choice but to hit and kill a pedestrian or to drive off a cliff killing the driver. Although Colin isn’t tackling the impossible feat of solving these ethical dilemmas, he is developing the language we need to communicate ethics to AI with the accuracy that we can’t achieve from machine learning. So who does decide how these robots will respond to ethical quandaries? While not part of Colin’s research, he believes this is best left answered by the communities the technologies will serve.
Colin doing a logical proof on a whiteboard with a 1/10 scale autonomous vehicle in the foreground.
The ArchIve: a (brief) history of AI
AI had its first wave in the 70’s, when it was thought that logic systems (a way of communicating directly with computers) would run AI. They also created perceptrons which try to mimic a neuron in a brain to put data into binary classes, but more importantly, has a very cool name. Perceptron! It sounds like a Spider-Man villain. However, logic and perceptrons turned out to not be particularly effective. There are a seemingly infinite number of possibilities and variables in the world, making it challenging to create a comprehensive code. Further, when AI has an incomprehensive code, it has the potential to enter a world it doesn’t know could even exist – and then it EXPLODES! Kind of. It enters a state known as the Principle of Explosion, where everything becomes true and chaos ensues. These challenges with using logic to develop AI led to the first “AI winter”. A highly relatable moment in history given the number of times I stop working and take a nap because a problem is too challenging.
The second wave of AI blew up in the 80’s/90’s with the development of machine learning methods and in the mid-2000’s it really took off due to software that can handle matrix conversions rapidly. (And if that doesn’t mean anything to you, that’s okay. Just know that it basically means speedy complicated math could be achieved via computers). Additionally, high computational power means revisiting the first methods of the 70’s, and could string perceptrons together to form a neural network – moving from binary categorization to complex recognition.
A bIography: Colin’s road to coding computer ethics
During his undergrad at Virginia Tech studying computer science, Colin ran into an ArachnId that left him bitten by a philosophy bug. This led to one of many philosophical dilemmas he’d enjoy grappling with: whether to focus his studies on computer science or philosophy? And after reading I, Robot answered that question with a “yes”, finding a kindred spirit in the robopsychologist in the novel. This led to a future of combining computer science with philosophy and ethics: from his Master’s program where he weaved computer science into his philosophy lab’s research to his current project developing a language to communicate ethics to machines with his advisor Hassam Abbas. However, throughout his journey, Colin has become less of a robopsychologist and more of a roboethicist.
Want more information on coding computer ethics? Us too. Be sure to listen live on Sunday, April 17th at 7PM on 88.7FM, or download the podcast if you missed it. Want to stay up to date with the world of roboethics? Find more from Colin at https://web.engr.oregonstate.edu/~sheablyc/.
Colin Shea-Blymyer: PhD student of computer science and artificial intelligence at Oregon State University
This week we have a PhD candidate from the materials science program, Jaskaran Saini, joining us to discuss his work on the development of novel metallic glasses. But first, what exactly is a metallic glass, you may ask? Metallic glasses are metals or alloys with an amorphous structure. They lack crystal lattices and crystal defects commonly found in standard crystalline metals. To form a metallic glass requires extremely high cooling rates. Well, how high? – a thousand to a million Kelvin per second! That high.
The idea here is that the speed of cooling impacts the atomic structure – and this idea is not new or limited to just metals! For example, the rocks granite, basalt, pumice, and obsidian all have a similar composition, but different cooling times. This even gives Obsidian an amorphous structure, which means we could probably just start referring to it as rocky glass. But the uses of metallic glass extend far beyond those of rocks.
(Left) Melting the raw materials inside the arc-melter to make the alloy. The bright light visible in the image is the plasma arc that goes up to 3500C. The ring that the arc is focusing on is the molten alloy. (Right) Metallic glass sample as it comes out of the arc-melter; the arc melter can be seen in the background.
Close-ups of metallic glass buttons.
Why should we care about metallic glass?
Metallic glasses are fundamentally cool, but in case that isn’t enough to peak your attention, they also have super powers that’d make Magneto drool. They have 2-3x the strength of steel, are incredibly elastic, have very high corrosion and wear resistance and have a mirror-like surface finish. So how can we apply these super metals to science? Well, NASA is already on it and is beginning to use metallic glasses as gear material for motors. While the Curiosity rover expends 30% of its energy and 3 hours heating and lubricating its steel gears to operate, Curiosity Jr. won’t have to worry about that with metallic glass gears. NASA isn’t the only one hopping onto the metallic glass train. Apple is trying to use these scratch proof materials in iPhones, the US Army is using high density hafnium-based metallic glasses for armor penetrating military applications, and some professional tennis and golf players have even used these materials in their rackets and golf clubs. But it took a long time to get these metallic glasses to the point where they’re now being used in rovers and tennis rackets.
Metallic glass: a history
Metallic glasses first appeared in the 1960’s when Jaskaran’s academic great grandfather (that is, his advisor’s advisor’s advisor), Pol Duwez, made them at Caltech. In order to achieve this special amorphous structure, a droplet of a gold-silicon alloy was cooled at a rate of over a million Kelvin per second with the end result being an approximately quarter sized foil of metallic glass, thinner than the thickness of a strand of hair. Fast forward to the ‘80’s, and researchers began producing larger metallic glasses. By the late ‘90’s and early 2000’s, the thickness of the biggest metallic glass produced had already exceeded 1000x the original foil thickness. However, with great size comes greater difficulty! If the metallic glass is too thick, it can’t cool fast enough to achieve an amorphous structure! Creating larger pieces of metallic glass has proven itself to be extremely challenging – and therefore is a great goal to pursue for graduate students and PI’s interested in taking on this challenge.
Currently, the largest pieces of metallic glasses are around 80 mm thick, however, they use and are based on precious metals such as palladium, silver, gold, platinum and beryllium. This makes them not very practical for multiple reasons. First, is the more obvious cost standpoint. Second, given the detrimental impact of mining rare-earth metals, efforts to minimize dependence on rare-earth metals can have a great positive impact on the environment.
World records you probably didn’t know existed until now
As part of Prof. Donghua Xu’s lab, Jaskaran is working on developing large-sized metallic glasses from cheaper metals, such as copper, nickel, aluminum, zirconium and hafnium. It’s worth noting that although Jaskaran’s metallic glasses typically consist of at least three metal elements, his research is mainly focused on producing metallic glasses that are based on copper and hafnium (these two metals are in majority). Not only has Jaskaran been wildly successful in creating glassy alloys from these elements, but he has also set TWO WORLD RECORDS. The previous world record for a copper-based metallic glass was 25 mm, which he usurped with the creation of a 28.5 mm metallic glass. As for hafnium, the previous world record was 10 mm which Jaskaran almost doubled with a casting diameter of 18 mm. And mind you, these alloys do not contain any rare-earth or precious metals so they are cost-effective, have incredible properties and are completely benign to the environment!
The biggest copper-based metallic glass ever produced (world record sample).
Excited for more metallic glass content? Us too. Be sure to listen live on Sunday February 6th at 7PM on 88.7FM, or download the podcast if you missed it. Want to stay up to date with the world of metallic glass? Follow Jaskaran on Twitter, Instagram or Google Scholar. We also learned that he produces his own music, and listened to Sephora. You can find him on SoundCloud under his artist name, JSKRN.
Jaskaran Saini: PhD candidate from the materials science program at Oregon State University.
This post was written by Bryan Lynn and edited by Adrian Gallo and Jaskaran Saini.