I chose this project originally because it felt different than other projects in the capstone options and smaller projects that I have done in previous OSU work. I also chose it because it sounded challenging and put me out of my depth in a way where I could push myself to learn more. I thought the idea of big data and algorithmic statistical processing sounded the most interesting to me.
What was difficult about this project?
The hardest part of this project was the math. I learned very quickly that I am a programmer and not a statistician. Thankfully I am in the right major then! But it did make this very hard, as in this project there was lots of work outside just programming. I spent many extra hours on this project writing formulas on paper so that I could better understand them to get correct results.
Who will use
The target audience for this library will be anyone in SCA who wants a library that is abstracted in a readable way. Hopefully it will show that it is easy to use and educational. The library is more geared to data people and SCA/EE people than it is software people; which is why we had to learn so much!
A numpty is defined by Cambridge University as a “stupid or silly person” and is how I feel when learning new technologies. I don’t mean to sound harsh, but to make a joke out of myself when trying to learn new things. For me, I have had to learn a lot of new technologies for my capstone including, sqlite3, HDF5 file format and thus h5py, NumPy, and more. All of which I have never touched.
Whats a NumPy?
Official Definition
NumPy is self described as, “…the fundamental package for scientific computing in Python. It is a Python library that provides a multidimensional array object, various derived objects (such as masked arrays and matrices), and an assortment of routines for fast operations on arrays, including mathematical, logical, shape manipulation, sorting, selecting, I/O, discrete Fourier transforms, basic linear algebra, basic statistical operations, random simulation and much more.”
And to be honest I didn’t really read that either, in fact I almost fell asleep during it. So… what does that giant block of text that someone way smarter than me wrote mean? First let’s look at the Python Language.
Interpreting Snakes
When I was a kid living in Virginia they explained the difference between Coral and Milk snakes who have the same colors. One is poisonous and one isn’t… they taught kids a rhyme, I can’t remember it; I just tended to avoid all snakes. Anyway, remembering interpretation vs. compilation is a lot like that when you are starting out as a programmer. You don’t exactly know whats different under the hood, but you know that you’re avoiding coding by using ChatGPT… just kidding ;), they didn’t have that when I started. But why do we need to compile some languages and not others? Well, compiled languages take what you have coded and turn it into machine code – compilers are built by really smart people. The machine code runs at lightning speed compared to interpreted languages which execute each command line by line. Compilers also help by reducing logic, where as interpreters don’t. In short, compilers take your code and reduce it to its best in machine code, and interpreted languages execute exactly what you code, no matter how good or bad. Python is the latter, interpreted (poisonous to speed). But it is very readable and writable.
The Numpty Definition of NumPy
Now please know that I’m definitely not calling anyone stupid, its more just fun alliteration to say that it IS okay to not know things and be bad at them when you are learning them, or you wouldn’t have to learn them!! So heres how I describe it:
NumPy is a Python library that is really just a Python wrapper around C (which is a compiled language) used for declaring and manipulating arrays in fancy ways. It allows the readability and writability of Python and the speed of C to come together.
Personal Experience using NumPy
I had never used NumPy before, I only heard it talked about and seen it put on job descriptions. It quickly has become a favorite library of mine and enjoy its ease of use. For example, my team needed a development tool to convert a sqlite file to an hdf5 file, but the SQL file was in rows and we needed to process by column. After lots of bad iterations involving lots of arrays being sliced and put back together and such I then found a way to do it with NumPy that was only a few lines of code and considerably faster than anything I could have come up with. First I got the SQL rows in a variable traces. Then I made that variable a NumPy array with np_traces = numpy.array(traces). After that, and this is the magic, I used numpy.stack(np_traces, axis=-1) and tada! – column order. After that the processing was easy.
New Tools
So, when you are learning new tools remember to give yourself grace and struggle with it, once you start to get it, it will be all the more rewarding, especially more rewarding than using ChatGPT haha. And if you come across a red, black, and yellow snake in the South remember, “Red touches black, friend of Jack. Red touches yellow, kill a fellow.” — I looked it up :).
The new term has started on this capstone and we really have hit the ground running in our team. There are lots of moving parts and lots of code to get our heads around. All of our development is in Python at the moment, and because of this I found an article on dev.to by Alex Omeyer who writes about tips on how to write clean python code.
Takeaways on Writing Clean Python Code
Naming
I always thought that short simpler names were more efficient in coding. In terms of writability that used to be true. With newer coding conventions like predictive suggestion (When you are in your IDE of choice and you type a declared var and you just have to press enter for the IDE to type it for you) you don’t have to type out the entire name of a function, variable, or class – most IDE’s do it for you. This means that names can be long and descriptive for the user to see.
See how descriptive it is! Now anyone on my team can see that this function only returns a generator for a row.
Do One Thing
This one is simple… at least it should be. I am lazy sometimes and have multiple functionalities in my function. Having your function do one thing well, if you need to do two things thats a subclass or a new function. This keeps things short, readable, and simple.
Keep it Modular
Upon visiting my home state of Oregon, USA, I go to MOD Pizza. At MOD they have steps. First Pizza base, then sauce, then cheese, then toppings, then extras. Each pizza is MODified, and their process is MODular. Our code should be like this too. Each feature, component, or part should be its own module. It doesn’t matter if thats a directory or its own .py file, thats up to your system design and needs. The point is that it should be separated into logical units that make sense to your team and future users/developers.
Smelling Your Code
How do you smell your code? Pro tip – don’t sniff your screen, senior developers will look at you funny. In an article on dev.to by Joe Eames they discuss how a code smell works and what they are all about; a code smell is a way of improving code beyond debugging and problems. A code smell is code that smells funny, it’s “off.” Some examples would be things like a function that does more than one thing, or a class that is thousands of lines long. Any code that can be improved by simplifying our code and making it less offensive, like lighting a candle after taco bell.
In Practice
Through the course of this term my team and I will continue to offer advice and critiques on each others code through code reviews. In this I believe that we can smell each others code through code reviews and all become better programmers together.
This project (looking at Big Data for SCA), was the most daunting project I have come across once it was fully explained to me. I didn’t know loads about encryption or big data, only bits and pieces. I didn’t know how to use the toolchain we decided on, I didn’t know a lot. Over the last 10 weeks I’ve learned more in a short amount of time, more than I thought I could; just in this last week I am finally feeling like I have a grasp on the project as a whole. For v0.0.2 we are starting to implement some basic parts of the library, so that we can spend more time optimizing our solution in the future. Overall, I am excited to learn more in actually developing this project till it is completed in the coming year.
Jobs
At the beginning of this term I was applying for jobs and I am happy to announce that following graduation I have been offered an Associate Software Engineering position at a company called Liberty IT here in the UK. It is nice to have some recognition and reward for all the work I put into this degree. To anyone on the job hunt best of luck!
Tech
In my learning for this project I am working with h5py, hdf5 files, and numpy. Numpy was a technology I had heard of but never actually got to using, so it has been nice to expand my knowledge base in that regard. Learning hdf5 has been a learning curve, but h5py makes it easier. The most challenging part will not be so much the technologies but optimizing in our library.
Life
Have you ever been so stuck on a problem that you spent all day in a debugger only to realize you typed ‘j’ instead of ‘i’? — Me too. My advice to anyone taking computer science classes, or developing in general, is to get up. When you’re stuck on a problem, get up and come back to it fresh eyes. I’ll go for a walk or get a coffee or snack, which ever it is it lets me come back to the problem and solve it in less time than staring at a debugger for hours.
The project I am working on for my capstone is statistically based with lots of computation; this makes the project very math heavy. Luckily in computer science the computer does a lot of the math for you, but you have to make sure that it is doing the math correctly in the first place. I have had to do a lot of learning very quickly in this capstone project.
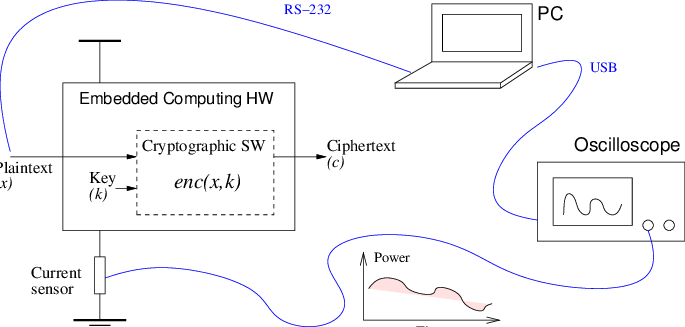
Side Channel Analysis (SCA)
Chip hacking. It sounds very cool, but practically, it takes a lot of equipment, knowledge and loads of time. Side Channel Analysis is reading the electromagnetic output of a process chip using an oscilloscope at different x, y positions on the chip. This output produces lots and lots of data that takes a long time to work through. That is why we are developing a statistical library to speed up the process.
Processing these large data sets requires lots of reading from files. So the first step is figuring out which file type we want to use to increase our read efficiency. The next step is figuring out how to collect basic statistics in an accumulative way in one pass over the data. Then using these statistics to then gain insight into the SCA. Then the steps after that will be about optimization.
The Course
So far I have really enjoyed the CS46X course. It has caused me to do lots of thinking and solve problems outside of the scope of simply an assignment brief. The course is a good hybrid into industry work that I am looking to start after graduation.
Jobs
In the UK there are graduate jobs – jobs specific to people leaving university and entering the work force. I have currently been turning in coding challenges for these jobs and am hoping to hear back for an interview soon. One of them has the possibility to start work in the cybersecurity scene which I would be excited for.
Technologies
In the process of this project there has been a lot of learning new technologies. I’ve learned about different binary file types and the pros and cons of each: hdf5, sqlite, and zarr. On top of that I have learned more about how the python language works and the global interpreter lock.
Flat White
Every morning I get up and make a flat white and I use it a reminder to take one day at a time because with projects this big and other classes on top of that while applying to jobs and doing code challenges for said jobs can be overwhelming. So to people who have a lot on remember to take one day at a time and do what you can. 🙂
Hey fellow data point generator! Thats you, and me! My name is Jadon and I live in Belfast, Northern Ireland (PST +8). I attend Oregon State University (OSU) through their Ecampus, and am working towards graduating with a B.S. in Computer Science. Outside of University I enjoy coffee, the ocean, and doing anything that gets my body moving – whether that be cold ocean swims, cycling, or hiking up a mountain.
Mt. Errigal, Donegal, Republic of Ireland.
Even though it was something both my dad and granddad were in, I never wanted to be in the software/computer game. However I somehow stumbled into the intro CS class at OSU (back when I was on campus) and haven’t looked back sense after changing my major. Ever since then I have enjoyed every second of learning; even the times when I accidently deleted a “}” and couldn’t find the error for hours. Easy to say I’ve come a long way from there (mainly because of linters… jk…I hope…), and now am settling in software engineering for big data in my capstone project for OSU.
We consumed 97 zettabytes of data as of 2022, and are consuming and generating more data every second according to Domo and their popular research blog and infographic: Data Never Sleeps. Thats 97 X 10^21, which equals: 97,000,000,000,000,000,000,000 bytes of data.
I have a new interest in data as it pertains to software engineering and the problems of having so much of it. In this blog I hope you the reader will go on a journey with me (a, more or less, complete newbie) where I learn from/with my team on how software engineers handle the modern problem of big data through our capstone project at OSU.
Let’s climb this metaphoric mountain of data together 🙂