
Apologies for the delay in posting! I wish to explain the past two weeks of planning and the beginnings of our project development, but let me first start with catching up on the beginnings of our group planning.
After our groups were determined, our group set up a Discord channel and met virtually to discuss our thoughts on our project. There were many ways to tackle our project, but after much discussion, we determined parallel development would be the best use of everyone’s time. After laying out our project plan, our roles, and planning our our Sprints, we started our progress towards our Sprint 1 goals!
To better outline my role in this project, I am the main program developer and the UI/UX designer. Outside of myself, there are 2 other group members in my development team. Emiope Mimiko is the audio pipeline developer and a CNN developer. Katherine Collier is the main dataset developer and also a CNN developer. Given our skillsets, since I have experience in UI/UX and Emiope and Katherine have experience with dataset development, this was the best delegation based on what each of us could provide to the project team. We all three have done extensive research to learn more about Tensorflow, Librosa, and NumPy arrays to best prepare for the future of this project (and those technologies will be used throughout).
In regards to the main program, here is a general breakdown of each Sprint goal:
Sprint 1–Build the structure of the main program. (CNN/pipeline development in parallel)
Sprint 2–Implement the CNN and audio pipeline in the main program completely.
Sprint 3–Develop web application user interface. (CNN/pipeline improvements in parallel)
For those who are interested, here is a general flowchart for the 3 sub-programs of our project:
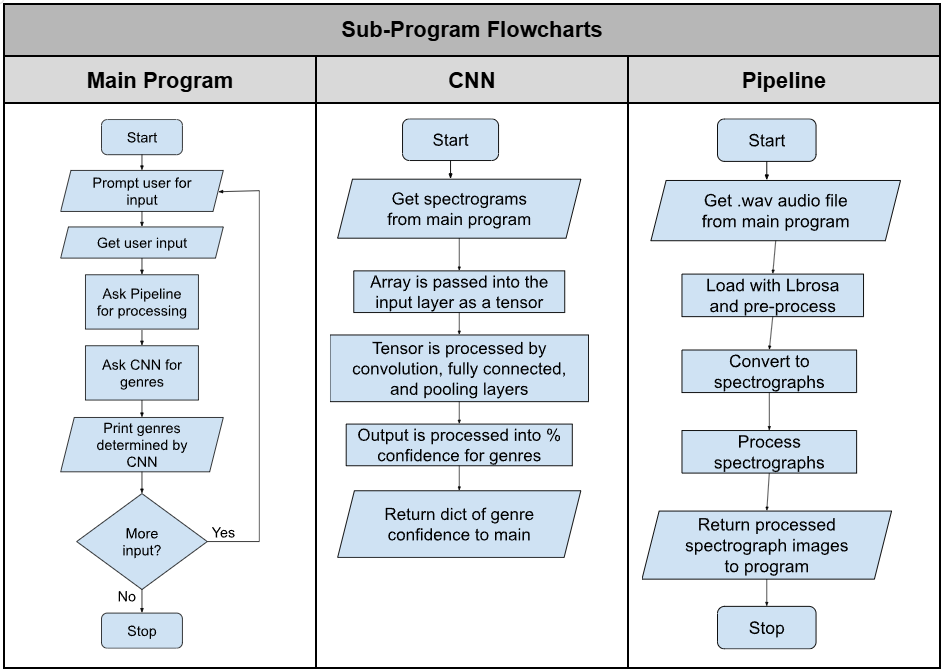
Our group began on Sprint 1 a week and a half ago and just recently met our goal. I will discuss Sprint 1 in another post, but this post is to simply explain the start of our program and the decisions we have made to move forward.
I will write again soon,
Kelsey Shanks