Hello everyone! Since my group has recently concluded our Sprint 1 goals, I feel it is an appropriate time to share how Sprint 1 went and, in particular, share an unexpected roadblock I encountered.
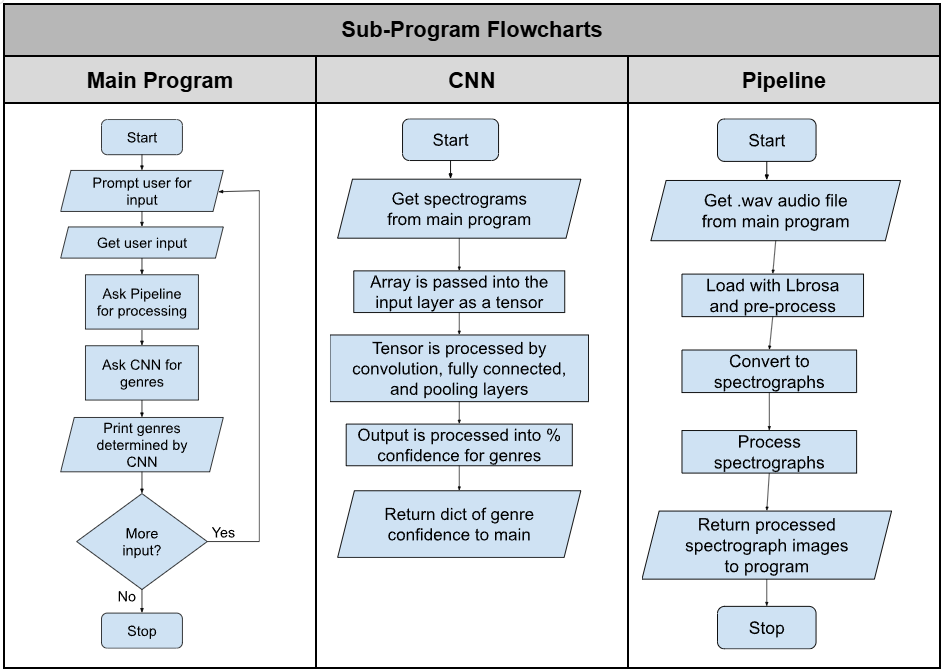
As a good general statement, Sprint 1 went well and our project has a very solid foundation to build off of. The main program displays information to the user, it takes user input and validates it, it calls a skeleton function that will later be the actual calls to the pipeline and CNN, and it uses a linked list structure to print the genres to the user. Over all, that is a success.
While developing the user input and validation functions, I did encounter issues with my original plan and had to adjust it to work with the program. I will explain below.
Originally, I planned to check the file content and the file extension when validating the user input. There is a library called “filetype” in Python that uses the OS-assigned mime type to perform a quick check on what the contents of the file are. My plan was to use that module in tandem with checking the extension (which was also possible using that library).
After trial-and-error of implementing this library and trying to debug the issue, I came to the conclusion that the library is no longer compatible with the most recent version of Python 3.12. The “filetype” library is compatible with older versions of Python, but after discovering the aforementioned incompatibility and deliberating (and considering another unsupported library called magic that uses magic numbers assigned by the OS), I decided that our project did not need this sort of dependency if I could help it. Therefore, I diverted to using the “pathlib” built-in Python library that is still supported in the latest version of Python. In this way, the external library dependency is eliminated and should continue to be supported if using a later version of Python in the future.
The solution using the pathlib built-in library:
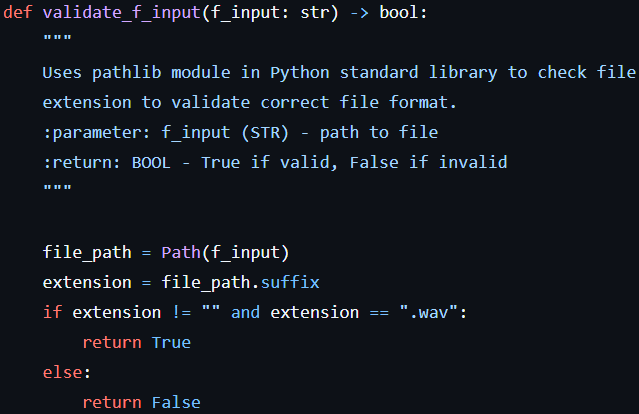
The only real set back this provided was (1) time spent researching the issue and (2) now the program only checks the file extension when validating the input. My thought is that, if we state to the user the format we accept (which the program does) and we do not allow incorrect extensions (which the program prevents), then the issue of a corrupted file is one that is relatively unlikely and can be ignored for now. I may try to implement additional validation later on, but the program performs enough validation for now.
I will write soon about further developments,
Kelsey Shanks