My Project
The project that I have been working on this year is a Top-N Genre Classification Neural Network. This neural network allows users to use a CLI app to detect the genres of user-provided audio files. The way that it classifies them is by generating a list of genres each with a numeric “confidence value”. These values describe how confident the model is that the genre matches the given audio clip.
This project is split into two main portions: neural network development and training, and the input preprocessing. Input preprocessing was my task which meant that I had to figure out how to convert the audio files into a format that the model could read. This is important for converting the user’s audio files and also for building the dataset that would train the model.
Why I chose it
The reason I decided to join this project is because of my passion for music and my knowledge of music theory. I have always wanted to combine my interest in computer science with my interest in music and this was the perfect opportunity to learn more. I once wrote a ‘Formal Proposal’ for a course of a project practically identical to the one we are working on now.
I also believed that I could provide a lot of insight into the musical aspects of the project. I have a lot of experience with playing music and studying theory. This made it easier to decide things like what genres to use and how to avoid biases when it comes to something so subjective. It also helped us decide whether to store data as spectrograms or mel-spectrograms.
What have I learned
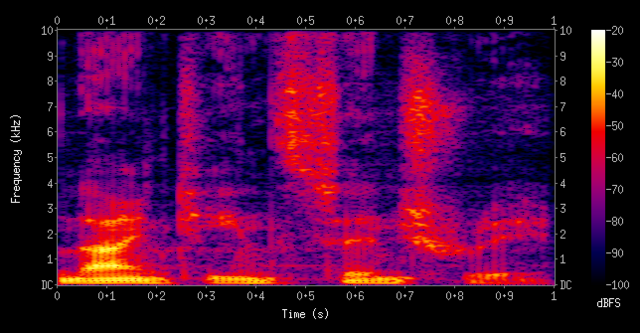
One of the biggest things that I have learned much more about is how computers interact with audio. I had never thought much about it before and it was very interesting to see how we can measure sound with computers. At first, we started with mel-spectrogram jpg images, a visual representation of audio as a graph of colors. This worked for a while but we eventually moved on to MFCCs which are the values of the spectrogram represented as a two dimensional array of numbers. Seeing these representations of audio was very new to me and working with them really helped me to understand how they are calculated.
I also unintentionally gained some knowledge on machine learning and how I can build my own in Python. I found out about the Tensorflow library and some standard procedures of how to build an accurate dataset to train a machine learning model. I also learned about the librosa library and how it can be used to process audio data in Python. All of this work has really grown my interest in AI and helped me get a better idea of what fields I would enjoy going into as I move forward with my career.