How do you approach learning something new, like a new technology?
Typically if the documentation is clear either on its own site or github repo I will start there especially for the installation of requirements. If things start to get a bit more confusing then I will check on YouTube for a tutorial if I think this could be a very long learning process to get the basics and then straight to Googling the questions that come up. More recently with chatGPT which I will expand on more, I have used it for various cases where it has been very helpful and other times where I felt like I was wasting time trying to think of how to ask a question so it would understand vs what normally would work in google to pull up a StackOverflow example. As far as time to learn stuff, I like to stick to 50 minutes on and 10 minutes off to not be overwhelmed and this cycle has helped me stay focused longer than just trying to power through. I usually get burnt out after about 3 hours max where as I can go significantly longer learning new material or just working in general following the 50/10 method.
Do you use chatGPT or other AI tools? In what way?
Yes, I have found that the use of chatGPT has sped up my production time quite a bit but at the same time for a little bit I felt like I was relying on it too much in such an important stage of my career I started to use it less. I found that I was getting more done but when asked to change something about the code I had chatGPT write it too just as long to understand it as it would have to originally learn it. This was a learning curve for sure as the tools are great until you are asked to be the expert on what you “wrote”. I can see this causing issues in the future if users are not careful to understand what is being produced before copy/ pasting and just trying to ship as soon as possible.
Mobile Chat GPT
I think the mobile version of this would be a great idea because you typically are not doing meaningful work on your phone other than messaging so an app would be essentially like google to quickly get an answer for recipes, a heated debate, or just casual questions alike.
What are some debugging methods you use. Do they usually work?
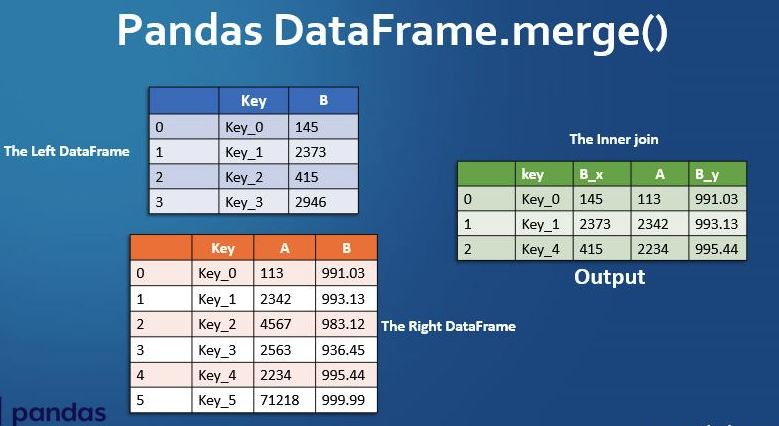
Right now I always quickly default to the good ole print method of debugging. This is a quick way to check what is happening in that moment what what values you have set to variables across the file. Another more recent way I have been using Python though is through Jupyter Notebooks and that has been pretty great since you can essentially debug every cell. It has been really helpful recently with this class and my work for data manipulation, checking to see what is inside the different pandas data frames after merges and such.
Building out a multi objective reinforcement learning model and creating custom indicators along the way is not something I would have been able to do or even think of doing before starting this course. Seems like stuff that Phd level individuals would be working on and so I am gladly soaking up all that I can with this project. I’m sure that the theories and more mathematical parts are covered for but the build itself I really need to know how to set these things up rather than building them from scratch. I am taking this course along with open source which has been a great pairing because I had no idea there were so many projects that were open source like Pandas for example. I guess I really didn’t know where it came from before taking these classes even though I had used it but that led me to try and find more libraries that I could use for this project. Learning new technologies has been the most rewarding so far and I think coming away from this class will help me in the future by going out and learning without much guidance. Other cool things on top of coding is learning about formulas in the financial world like the one here:
Learning about all the indicators has been interesting to know how to trade in the future and this is something that I will be looking into for much longer than the duration of this course.
Tools and Style
So my team is based in all different time zones so there can be commits happening at all times of the day. Since this project has taken a lot of research at the beginning it started off a little slow just to get our bearings but has ramped up pretty quickly and commits are starting to come in daily. For our project tracking we have been using Jira to make sure that our deadlines are being met and that we are all on the same page with what work needs to be done to hold each other accountable. I find it pretty easy to use since I use it at work and its so nice to have such a simpler board to keep us focused without customer bugs and tech debt that has built up over the years.
Success?
I think we will get a working product for sure. If it ends up tanking our paper trading accounts is another but we are definitely trying to optimize the strategies as best we can. We have been using the backtesting library which you can fine tune to give some insane results but of course hind sight is 20/20. I think we will get a better idea of profitability when we feed all the features into the model and train for the signal or buy or sell coming up in the next two weeks. This is the part that gets really exciting and seeing the sample models start to learn with the data we present. I started out by giving the lunar lander sample a go and helped the idea behind reinforcement learning get more solidified.
Overall I feel good about the project at this point and excited to see how we wrap it all together in the coming weeks! Check out my most recent post here!
Why did you and your team choose the technologies you did?
There are plenty of technologies to choose from for machine learning and artificial intelligence. With the explosion of AI, specifically OpenAIs ChatGPT, it seems like there is a new technology every day that can enhance and optimize our lives in large and small amounts alike. Taking what is complex and turning it into a simple interface makes work that would take hours and days turn into minutes and even seconds. So where do you go to find great tech for the specific task of creating a crypto trading bot trained with multi-objective reinforcement learning? Well it seems that there are a few options at this point and from what we gathered we just have to select a few and blend them together to make essentially our own tech stack for this project. We start with the basics of python given that it is the go to language for problems like this and with the popularity of Jupyter it felt like we would be able to train and test models most efficiently using that power duo. We also need to consider using Pandas, Scikit-learn, and NumPy, popular libraries for Python in their own right, for this project so we could accurately define a data set and structure it in a meaningful way. Preprocessing is a large part of the project so we are working with quality data and that can’t go overlooked, otherwise our results may not be accurate at all. We found that the ease of use and accessibility of yfinance would work well for our purposes and has done just that so far.
Reinforcement Learning. Figure 1.
Now once we gather the data and clean it what is next? Training, of course. For that we opted for sponsor and instructor guidance of TensorFlow and even OpenAI’s Gym to use as the environment. With so much buzz around the company and their products it seems like a great chance to learn more and get involved at such an early stage.Together we found that these technologies can all come together to build an amazing product and we are excited to present our findings!
How will your project use them?
When we build a machine learning model, our main goal is to create a model that can make accurate predictions on new, unseen data. To achieve this, we need to ensure that our model is not only good at fitting the data it has seen but also generalizes well to new data. The dataset we have is usually divided into two parts: the training set and the testing set.
Figure 2.
Training set: This is the part of the dataset that we use to “teach” or “train” our machine learning model. During the training process, the model learns patterns and relationships between the input features (e.g., characteristics of a flower) and the output (e.g., the flower’s species). Another example would be input of student study hours and output would be their grades. The model adjusts its internal parameters to minimize the error between its predictions and the actual output values in the training set.
Testing set: This is the part of the dataset that we use to evaluate the performance of our trained model. We do not use the testing set during the training process, so it represents new, unseen data for the model. By comparing the model’s predictions on the testing set with the actual output values, we can estimate how well the model will perform on real-world data that it has never seen before.
So using each of the technologies discussed previously are shown in Figure 2. Python is the base language across the entire project with the modeling taking place in Jupyter notebooks to aid in efficient memory usage and only training data once vs running large data sets over and over again each time we make an adjustment to the algorithm. The reason we use NumPy arrays instead of built-in Python lists is that NumPy arrays are more efficient for numerical computations, which are at the core of machine learning algorithms. NumPy provides a wide range of built-in functions for performing mathematical operations on arrays. These functions are highly optimized and easy to use, making it convenient to work with arrays. Scikit-learn is a great library for ML related tools like when we create a LinearRegression model object, we’re instantiating an object from the LinearRegression class provided by Scikit-learn. This class has several methods, including the fit() method, which is responsible for training the model using the provided input features and target values. OpenAI’s Gym makes setting up models super easy, like 5 lines of code easy. It really is the only exposure to training models I have to this point but I can say I can’t see it getting much better than this. Here is an example snippet:
import gym
from my_custom_environment import MyCustomEnv
from mo_dqn import MODQN
# Create the custom environment
env = MyCustomEnv()
# Initialize the multi-objective DQN agent
agent = MODQN(env)
So as you can see, we can quickly build off existing MORL agents and just get to testing.
What are their pros and cons?
Well initially the cons are that there are paid versions of what we are trying to do so depending on your financial situation you may be able to use for example quantconnect and build this out in a matter of minutes, including connecting to a brokerage of your choice and executing the trades. I guess that could be considered a pro as well. I think that for the enjoyment of learning though I will stick with the con side of view because I want to learn how to do it vs just using someone else’s product. I think that the pros of using all this tech comes with the failures and iterations that will surely have to be made because it just means that we are learning and building a tool suite of our own for future projects. It is one thing to say I made money with a bitcoin bot but it is another to say that you developed the bot itself. Even better would be to say that you in some manner sold the bot, whether through subscription or what ever else. At the end of the day the guys that made the most in the gold rush were the ones selling shovels and pans, not the gold miners themselves so I think that is the overall pro of using the tools we selected and the learning that comes along with them.
My name is Ben Burdett, and I am a solutions/integration engineer at a San Francisco-based start-up, working remotely from Florida. While I’ve been working with data integrations for almost 2 years now, I find myself experimenting with technologies related to stock trading and political interests in my free time. I enjoy making work more efficient, and with the recent surge in AI, I find the field all the more compelling.
Why Computer Science?
After graduating from Virginia Tech, I took a position as an operations manager at a start-up, where I wore many hats, including optimizing workflows, product procurement, managing teams of up to 40 members, and creating a marketing vision for the company. During this time, I became interested in technology and computer science while working on the company website, optimizing SEO, keywords, and hyperlinks to create a fluid site map for Google to crawl. This opened my eyes to a world I never knew existed, leading me to earn a second bachelor’s degree in computer science. While continuing to work in the construction industry, I set aside nights and weekends to pursue this degree, eventually landing a position as a data integration consultant just six months into the program.
Why did you choose the projects you did on the survey? What makes them interesting to you?
I’m passionate about smart investing and have a fun track record in this area. I’m excited to explore the possibilities of AI in this field and learn how it works. The buzz around AI is compelling, and I want to stay ahead of the curve. I have been experimenting with OpenAI’s ChatGPT and of course am very intrigued with AI and NLP the more I dig in. I also have used Binance’s API before and feel that I would know where to stat from day one to get that implemented for the crypto project. Trading is fascinating and build a software to make that either more accessible, user friendly, perform better, or a little of all would be something I truly find enjoyable to finish up this program.
What do you hope to learn from your project?
My ultimate goal in this course is to code every day and make my GitHub account shine bright green. I want to create a project that I’m proud of and build relationships with new programmers while learning from each other. I really want to use all the material I have learned over the past 2 years and solve a real world problem that maybe one day could be “the next big thing.” There are also no AI courses that I was able to take while in the program and would love to get a foot in the door for future employment opportunities.







 I’m passionate about smart investing and have a fun track record in this area. I’m excited to explore the possibilities of AI in this field and learn how it works. The buzz around AI is compelling, and I want to stay ahead of the curve. I have been experimenting with OpenAI’s ChatGPT and of course am very intrigued with AI and NLP the more I dig in. I also have used
I’m passionate about smart investing and have a fun track record in this area. I’m excited to explore the possibilities of AI in this field and learn how it works. The buzz around AI is compelling, and I want to stay ahead of the curve. I have been experimenting with OpenAI’s ChatGPT and of course am very intrigued with AI and NLP the more I dig in. I also have used