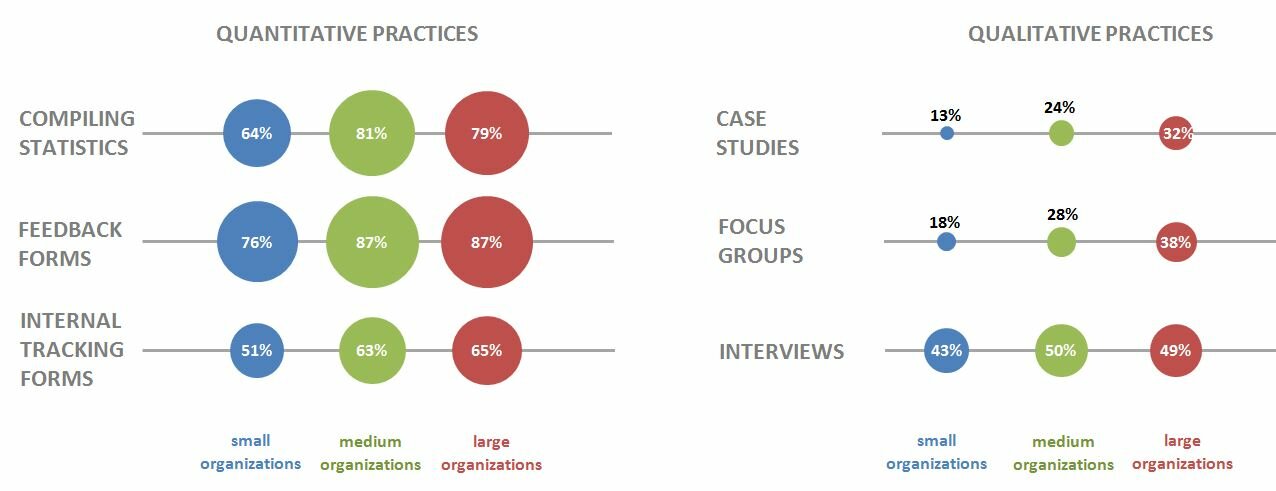
Wow! 25 First Cycle and 6 Second Cycle methods for coding qualitative data.
Who would have thought that there are so many methods of coding qualitative data. I’ve been coding qualitative data for a long time and only now am I aware that what I was doing was, according to Miles and Huberman (1994), my go-to book for coding,  is called “Descriptive Coding” although Johnny Saldana calls it “Attribute Coding”. (This is discussed at length in his volume The Coding Manual for Qualitative Researchers.)
is called “Descriptive Coding” although Johnny Saldana calls it “Attribute Coding”. (This is discussed at length in his volume The Coding Manual for Qualitative Researchers.)  I just thought I was coding; I was, just not as systematically as suggested by Saldana.
I just thought I was coding; I was, just not as systematically as suggested by Saldana.
Saldana talks about First Cycle coding methods, Second Cycle coding methods and a hybrid method that lies between them. He lists 25 First Cycle coding methods and spends over 120 pages discussing first cycle coding.
I’m quoting now. He says that “First Cycle methods are those processes that happen during the initial coding of data and are divided into seven subcategories: Grammatical, Elemental, Affective, Literary and Language, Exploratory, Procedural and a final profile entitled Themeing the Data. Second Cycle methods are a bit more challenging because they require such analytic skills as classifying, prioritizing, integrating, synthesizing, abstracting, conceptualizing, and theory building.”
He also insists that coding qualitative data is a iterative process; that data are coded and recoded. Not just a one pass through the data.
Somewhere I missed the boat. What occurs to me is that since I learned about coding qualitative data by hand because there were few CAQDAS (Computer Assisted Qualitative Data Analysis Software) available (something Saldana advocates for nascent qualitative researchers) is that the field has developed, refined, expanded, and become detailed. Much work has been done that went unobserved by me.
He also talks about the fact that the study’s qualitative data may need more than one coding method–Yikes! I thought there was only one. Boy was I mistaken. Reading the Coding Manual is enlightening (a good example of life long learning). All this will come in handy when I collect the qualitative data for the evaluation I’m now planning. Another take away point that is stressed in the coding manual and in the third edition of the Miles & Huberman book (with the co-author of Johnny Saldana)  is to start coding/reading the data as soon as it is collected. Reading the data when you collect it allows you to remember what you observed/heard, allows/encourages analytic memo writing (more on that in a separate post), and allows you to start building your coding scheme.
is to start coding/reading the data as soon as it is collected. Reading the data when you collect it allows you to remember what you observed/heard, allows/encourages analytic memo writing (more on that in a separate post), and allows you to start building your coding scheme.
If you do a lot of qualitative data collection, you need these two books on your shelf.