Our OSU Capstone journey into machine learning.
James Ramsaran | Daniel Fontenot | Trevor Phillips
Hello! This term, our team of enthusiastic student developers is venturing into machine learning (ML) for the first time. This blog will serve as a brief summary of the significant moments in our efforts and seek to be a resource for future students.
Let’s cut to the chase. Here’s what we had accomplished prior to our training efforts:
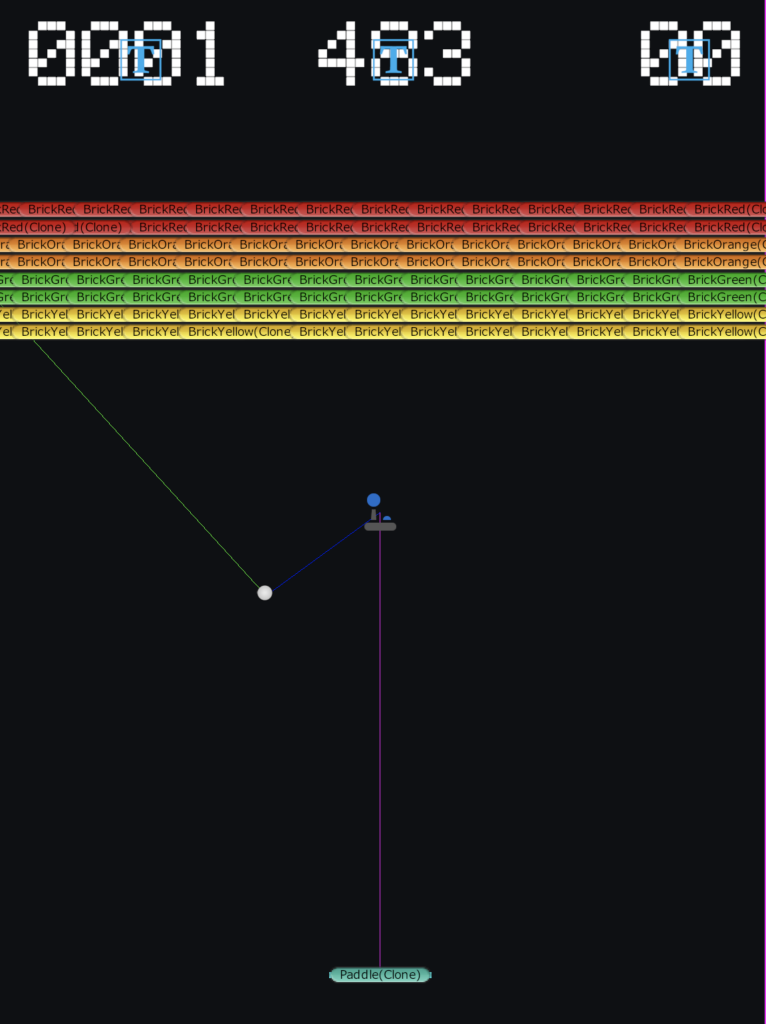
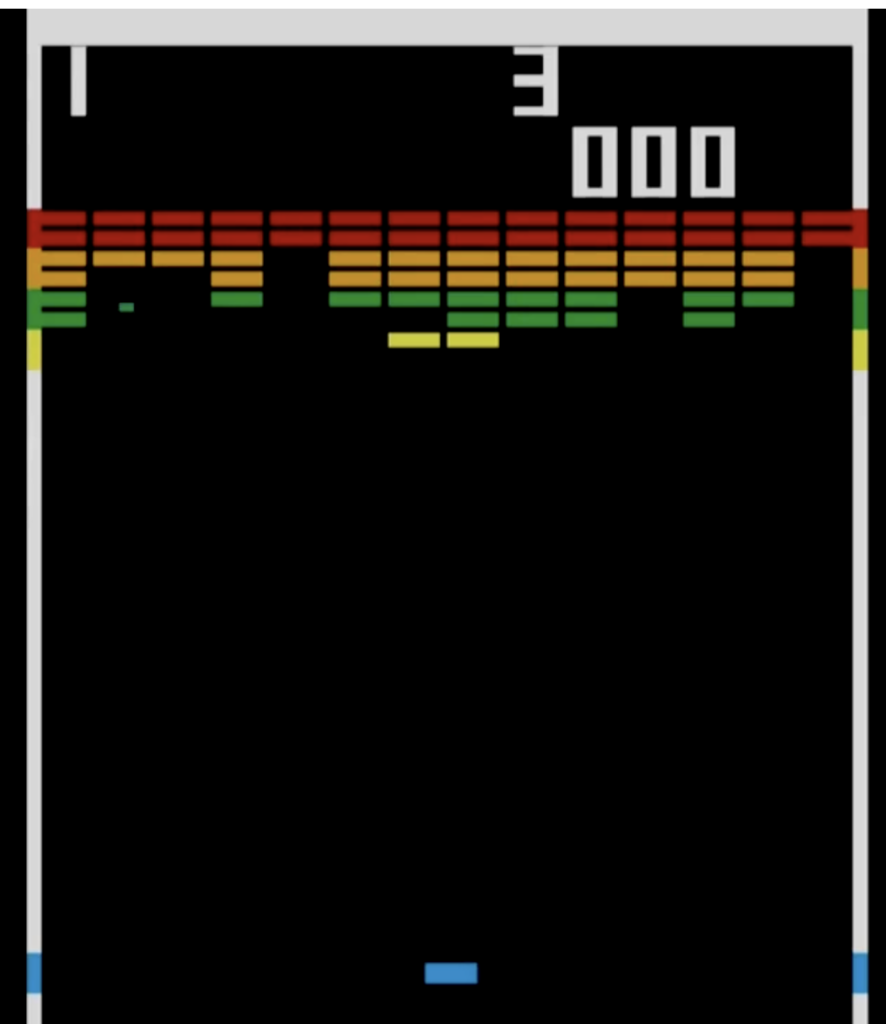
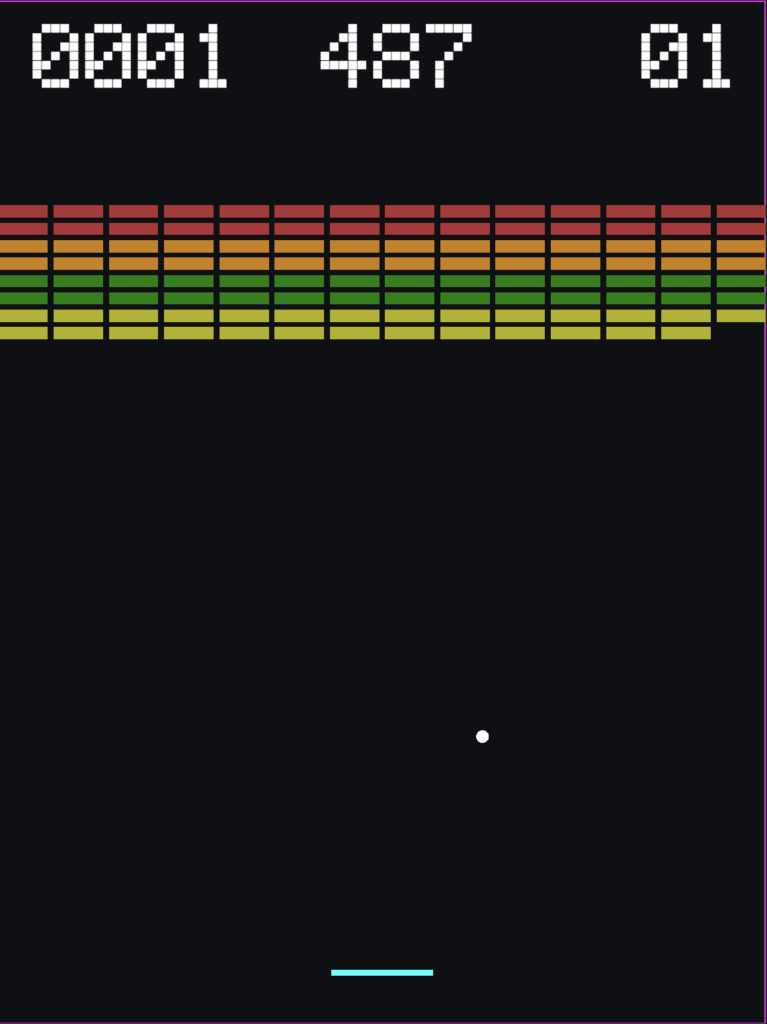
- Initial prototype our breakout clone built in Unity. We based our prototype (right) off of the 1976 Atari version (left).
- Installation of the ml-agents toolkit via the GitHub repo (https://github.com/Unity-Technologies/ml-agents/blob/develop/docs/Installation.md). Warning: This is currently (as of July, 2024) a major pain still on an ARM-based Mac M1 setup. Lots of troubleshooting required.
With these preparations in place, we set about constructing our first agent script for the paddle. To newcomers: while it might seem overwhelming at first the basic functionality of an agent script can be divided into three categories:
- Observations
- Actions
- Rewards/Penalties
Let’s look at each briefly.
Observations: Observations represent the data that the agent will track during the course of training. For our first training runs we are collecting three observations:
- The angle between the paddle and ball.
- The position of the ball.
- The position of the paddle.
// Relevant observations for agent.
public override void CollectObservations(VectorSensor sensor)
{
sensor.AddObservation(PaddleBallAngle());
sensor.AddObservation(ball.transform.position);
sensor.AddObservation(paddle.transform.position);
}Actions: Actions represent what the agent is able to do within the environment. For instance, a car agent might be able to accelerate and decelerate. Our paddle agent has three potential actions. The ML agents trainer of course doesn’t control these actions directly. It simply produces an integer for each decision:
- 0 = Stay still
- 1 = Move left
- 2 = Move right
We must then connect that integer to a meaningful action via code. In our model this is accomplished by accessing the paddle script.
// Control paddle movement
public override void OnActionReceived(ActionBuffers actions)
{
int dir = actions.DiscreteActions[0];
if(dir == 0)
{
//stay still
}
else if(dir == 1)
{
paddle.GetComponent<Paddle>().PaddleMoveLeft();
}
else{
paddle.GetComponent<Paddle>().PaddleMoveRight();
}
}Rewards/Penalties: Finally, in order to train the results must have meaning to the agent. This is accomplished through rewards and penalties. Our model begins with a very simple system:
- Ball is bounced: +5
- Ball dies: -100
// Reward bouncing ball
private void OnCollisionEnter2D(Collision2D other)
{
if(other.gameObject.GetComponent<Ball>())
{
AddReward(5.0f);
}
} private void Update()
{
// If ball dies give penalty.
if (deadBall)
{
AddReward(-100.0f);
}
}The goal here is straight forward. Can we train an agent to keep the ball alive by continually bouncing it off the paddle? Let the training begin!


One reply on “Training the Paddle”
Hi, this is a comment.
To get started with moderating, editing, and deleting comments, please visit the Comments screen in the dashboard.
Commenter avatars come from Gravatar.