
What Is Parallel Signal Processing?
To understand this concept, one first has to understand the fundamental ideas of signal processing and parallelization.
Signals are methods of conveying information. These generally come in the form of waves, which can be measured as a variation in some metric over time. An example of this would be a sound wave which contains information based on air pressure over time. The most common form of information-carrying-wave in embedded systems would be an electrical wave which is measured as a voltage over time.
The information contained in a wave may be encoded in a way that makes it difficult to interpret readily. This demands the creation of techniques for manipulating and interpreting the data, also known as processing. Processing techniques can vary widely depending on the type of signal and the information contained within. Some common examples of signal processing are:
- Speech recognition
- Audio amplification (speakers, hearing aids)
- Autonomous driving
- Image processing
- Video streaming
- Wireless controller input
Parallelization is a technique used on systems to increase throughput (system output as a function of time). While a system that consists of a single version of each processing component will only be able to process one piece of data at a time, a system that has each of its components working in parallel is able to process several pieces of data simultaneously. Shown below are the differences in processing time between a serialized system and a parallelized system:
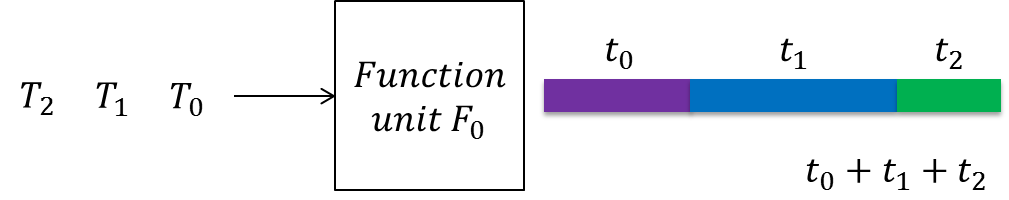
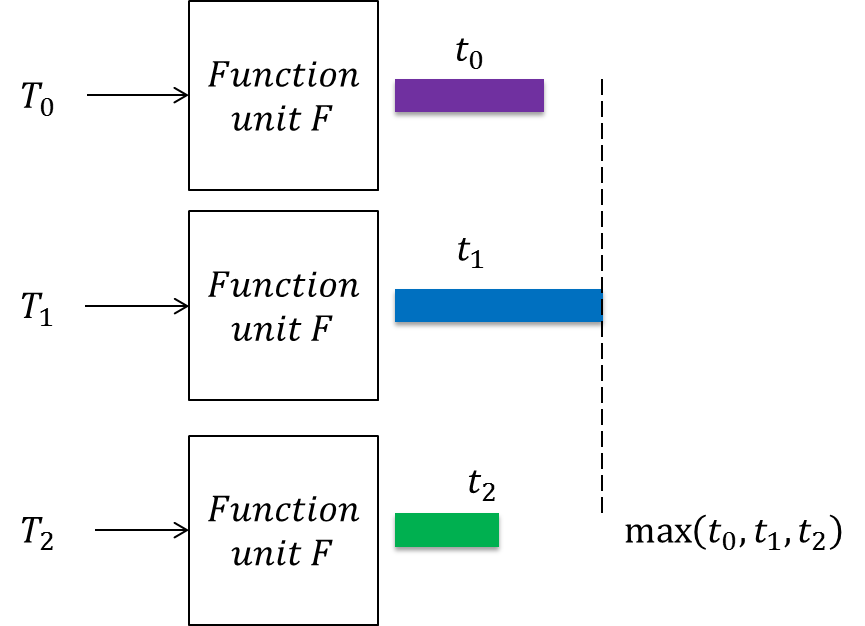
Parallel Signal Processing is the application of parallelization to any system that deals specifically with signals. The result is a system with improved throughput for processed data. This is particularly useful for embedded systems which contain some form of data processing that is time-critical. When the system has a limitation on how much time it can spend processing each piece of data, it may become necessary to parallelize the pieces to speed things up. For more information check out this resource.
Parallel Embedded Computing Architectures
This resource was written by Michael Schmidt, Dietmar Fey, and Marc Reichenbach of Friedrich-Alexander-University in Erlangen-Nuremberg Germany. The article discusses how the mid 2000’s experienced a dramatic change when it came to increasing computing performance due to the introduction of parallelism, also known as parallel signal processing.
Some of the topics discussed include task parallelism vs data parallelism, principles of embedded multi-core processors, memory-management in embedded systems, and the convergence of parallel embedded computing and high performance computing. Ultimately, the switch made to implementing multi-core processors was crucial to the capabilities that we now see with computers today.
Practical Impact of Parallelization
As mentioned above, programming to include parallel signal processing can have massive performance gains, and allows utilization of more CPU cores and threads. However, some workloads tend to benefit much better from this technique than others. One example of a task that benefits greatly, is video editing and production work. This has to do both with the type of task, and the method of programming that allows usage of more threads to speed the project rendering time.
In the research paper, The Landscape of Parallel Computing Research: A View from Berkeley, the researchers explore the diminishing returns present from parallelization. Most programs make most extensive use of a few cores or threads, and even the highly parallelized programs see diminishing performance returns after having a certain number of cores. This loss can potentially be mitigated against by higher per core efficiency, as well as writing smarter algorithms for optimal efficiency.
On-Chip vs. Off-Chip Parallel Processing
Digital Signal Processing is now used in a variety of different applications, and has become an increasingly attractive option due to the decrease in single-chip DSPs. With cheaper DSPs, manufacturers can use multiple, or parallel, DSP implementations that benefit from higher throughput and real-time processing capabilities. There are two types of parallel processing enhancements: on-chip and off-chip implementations.
On-chip parallel processing involves strategic architectural enhancements to better increase throughput of each instruction. One approach is through superpipelining, which is a technique that separates instructions pipelines into even smaller pipeline stages. With this, processing for the next instruction can occur before the current instruction finishes. Another technique is through superscaling, in which the chip’s architecture contains multiple pipelines, each executing its own instruction simultaneously. Research is currently being implemented on a Multi-CPU integration method, in which multiple CPUs lie in a single silicon, each processing its own unique instructions.
Off-chip parallel processing is needed to address the shortcomings of on-chip methods. Because there is always a throughput limitation for how efficient pipelined approaches are, off-chip methods such as multiple processor integration has been a big point of research. Unlike the Multi-CPU on-chip integration method described above, off-chip parallel processing takes advantage of multiple different processors and combines them through a unique processor-to-processor approach. Due to this, all of the on-chip parallel processing benefits still remain for each individual processor, but additional hardware can easily be added depending on the performance requirements.
Implementing Parallel Processing in code
Writing code that takes full advantage of the parallel capabilities of CPUs, and even GPUs , used to be difficult unless you were very good at writing assembly. With parallel computing being more necessary, and with hardware being more capable of parallelizing instructions, a consortium of companies created OpemMP (Open Multi-processing). OpenMP is an API built to work with C/C++ and Fortran that lets programmers easily create threads in the “fork-join” method. Programmers can give instructions to each thread individually or use the compiler directives to let the API handle the thread creation and work assignment. It is open-source and contains a lot of optimizations. With OpenMp and CPUs increasing their thread count and processing power, it is really simple to integrate parallel processing in your C/C++ code.
Implementing parallelism in GPUs is slightly different. GPUs are a little more inflexible compared to CPUs. However, this means they are very fast when you have to do many, many repeated calculations. They are specialized for that type of work. The performance in a GPU drops when you ask it to do something more generalized, like follow a linked list in memory. There is a similar API (also maintained by a consortium of companies) to simplify using a GPU. This API is called OpenCL. It works similarly to OpenMP, just on a GPU instead. Nvidia has their own API called CUDA, which is optimized for Nvidia graphics cards, and only works on their own graphics cards. OpenCL works on every graphics card that has the proper drivers (including Nvidia graphics cards).
