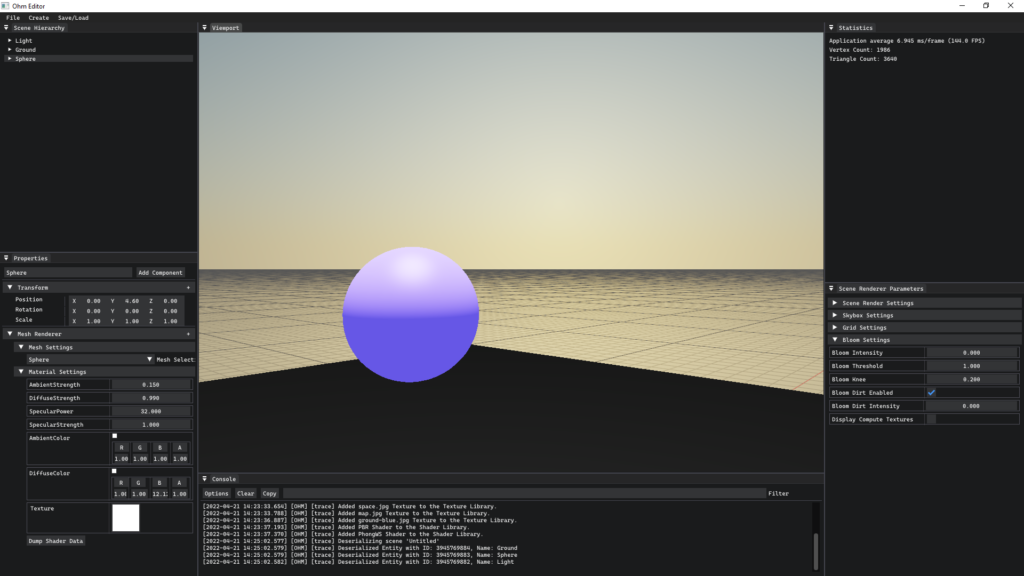
Volumetric lighting is a means by which games/interactive 3D applications/animations/etc. attempt to provide a sense of depth and atmosphere to a scene. Many times, this depth and atmosphere is communicated via clouds, dust, atmospheric debris and fog, just to name a few. Unsurprisingly, many of the techniques that provide the means to render these volumes of particles are the most hardware intensive. And if you think about this intuitively, it actually makes a ton of sense! If we want to deliver the most realistic looking clouds in a scene, we’re likely required to do our absolute best not to cut corners and model our clouds as close to the ones we can find in the real world. So we’ll start our journey into Volumetric Lighting here in the real world!
Let’s take a look at clouds because they’re the most clear (or not so clear! … sorry) examples of a “volume of particles” that give way to a particular interaction with particles and waves of light. While it may be obvious, it’s worth noting that a cloud is the sum total of (relatively) larger particulates in a given region of the atmosphere. Depending on the conditions of those various points within the atmosphere, we may see big, fluffy cumulonimbus clouds or lighter, wispier stratus clouds, or a seemingly infinite variety between those ends of the spectrum. So with that in mind, we can begin to construct a more intuitive understanding of how the light that travels through a cloud enters our eyes!
The first thing concept to cover is how light is understood. And don’t worry, you don’t need any real mathematical or physics-based background to follow this, because I don’t have either of those! We can think of light, referred to as photons, as particles that are emitted as radiation from the Sun. There are many “sizes” of these particles, or wavelengths. And you may remember the term “visible spectrum” from high school science. This spectrum refers to wavelengths of light that fall within a certain length – specifically, lengths that we can perceive visibly. On one end of the spectrum, we have red light, which has longer wavelengths and on the other, violet, which, you can imagine, has a much shorter wavelength. Now, the reason this wavelength matters for our clouds is that we can think of the different wavelengths having different interactions with the particles that just sort of hang around in the atmosphere. For example, what different interactions between a photon with a longer wavelength, say red, and an ozone particle vs. that same ozone particle and a photon with a shorter length, say blue, can we expect? Well, what tends to happen is that photons with shorter wavelengths tend to “scatter”, or collide, with more particles. The reason for this is surprisingly intuitive. Imagine for a moment we have a straight line representing the trajectory of a given photon.

Here we have our red line, a straight line. Next to our red line are two points. Let’s think of these two points as ozone molecules, and let’s think of our red line as a photon with an infinitely long wavelength, and in this case, it’s linear. We can view the y, or “up” axis, as time, and the x axis as the position of the particle. So at any given time, we can track the position of our particle. Given this fictitious scenario, the photon never intersects with an ozone molecule. But what if the wavelength were to change?

I’ve kept our original, linear line but changed its color to black and I’ve updated our new line to have the color red. We’ll think of this red line as a photon with a “red” wavelength. What’s interesting about this is that a shorter wavelength gives way for more opportunities for the photon to intersect with the molecules. Now, in reality, when that photon collides with an ozone particle, it doesn’t keep traveling along the same trajectory, but we’ll set that logic aside! Let’s take this one more step and another photon.

Now we have a third line, representing a photon with a violet wavelength – i.e. much shorter! What we can observe here is that the photon traveling along the violet line intersects with the green ozone particle and comes quite close to the blue one! With this thought experiment aside, I hope you can see why certain wavelengths of light interact differently with molecules that take up residence in our atmosphere!
So what determines the color of, well anything? You might ask. Well, the full answer goes beyond the scope of my knowledge, but to keep it short and hopefully sweet, imagine that our little violet photon bounces around the atmosphere for a few nanoseconds, jumbling up its trajectory and throwing it all over the place, eventually making its way down to planet earth. And let’s just say for a moment that that same little photon collided with something, say a leaf. Let’s just say that YOU were looking at that leaf at roughly the same time. Why isn’t the color of the leaf violet? Well, the color of the leaf is the sum of the parts of the visible spectrum that it DOESN’T absorb. This means that the leaf will soak up all of the other wavelengths of the visible spectrum except for green! So at that exact moment you were looking at the leaf, a whole host of green photons were scattered into your eye, giving you the means by which to interpret the leaf!
This scattering and viewing phenomena is often referred to as transmittance. Specifically, transmittance is the quantity of light that passes through a solution. What is the solution you may ask? The leaf? No, it’s the air between you and the leaf! And we’ve already discussed the absorption part of light, which, no surprise, is referred to as absorbance. Which is sometimes referred to as optical density (OD) and is the quantity of light absorbed by a solution. Fortunately for us, there have been some pretty smart folks in charge of understanding this phenomenon far better than I! Two gentlemen gave way to a law that is now formally known as the Beer-Lambert law, or just Beer’s law. There are many uses for Beer’s law, but the one we’re particularly interested in has to do with stellar radiation as it travels through planetary atmospheres. This law essentially states that the denser a medium, the less light we can expect to travel through. This is also pretty intuitive – if I shine a flashlight into a relatively clear hallway, I’ll see that the light travels through successfully. However, if I shine a flashlight into a hallway filled with smoke, there’s a chance I won’t be doing anything but lighting up the smoke!
Now, the reason that the smoke in the hallway appears darker than the fluffy clouds in the sky has to do with how the molecules of the smoke interact with the light. In the case of the smoke, the molecules will “capture”, or absorb, this light so that it will rarely be transmitted back to your eyes. And when it is transmitted back, we certainly won’t be seeing the full visible spectrum – i.e. the color white. On the contrary, the clouds that appear white a fluff, like the ones below, end up scattering more light which eventually ends up in your eye. But it’s not just that the clouds scatter more light, they scatter all wavelengths of light! This means that the wavelengths of light that the molecules in the cloud end up scattering fit the entire visible spectrum, giving them a white appearance!

However, the more thick and dense a cloud is, the less light ever gets the chance of exiting, giving the darker clouds their more ominous appearance! This is because the thicker a cloud gets, the more water droplets and ice crystals gather. The more these molecules gather within the cloud, there are more opportunities for larger molecules to scatter the light between each other and more opportunities for the molecules to absorb this light.

While I haven’t done an in-depth explanation as to how rendering engineers model this phenomena in 3D applications, I hope this brief introduction has given you a taste of what goes into simulating light interactions with participating media like clouds and fog. I’ll leave the more technical, rendering explanation for another post! Regardless of whether you’re a rendering nerd like me, I hope the next time you walk outside you spend an extra second appreciating the clouds.