Seeing as how I haven’t done too much in the way of using this platform as a way to write about progress for the Capstone project, I figured now was as good a time as any. My motivation for documenting the development progress of “Virtual Bartender” isn’t because I’m particularly motivated at this moment; nor is it because I’m really leaning into accountability or transparency with the development of this project. I think it’s because I’d like to flesh out some thoughts that generally tend to come up around this point in a somewhat involved project. Specifically, I’ve noticed that I often face an interesting double-edged sword: a truly inspiring, motivating, imaginative state of mind that marks the entry into a project – this tends to be characterized by diagrams, drawings, mind-maps, inspirational art, prototypes, you name it – which is swiftly met with the colder reality that a project almost never meets my unrealistic, imaginative expectations. This often leads me to adding another body to my “dead-projects” folder left to rot somewhere in my C drive.
Alright, enough of the downer negativity! I really don’t want to be a drag, so bear with me here. Because here’s the thing that I’ve realized: all of that day-dreaming about the projects I come to love (and often hate) is ultimately the lifeblood of being a developer, a creator. I guess what I’m getting at is the two are inextricably related. I won’t have motivation for a project if I don’t get inspired – or I need to eat, which is an entirely different topic. However, my inspiration usually comes from an … “out-there” place – movies, music, pictures, dreams, day-dreams, etc. So if my inspiration is born from an imaginary place, which often leads to unrealistic expectations and an inevitable let down, what’s the solution? Well, I certainly don’t have a one-size-fits-all solution, but I’ve slowly been compiling my experiences which have guided me to, at the very least, a bit of awareness and a few tools that tend to help.
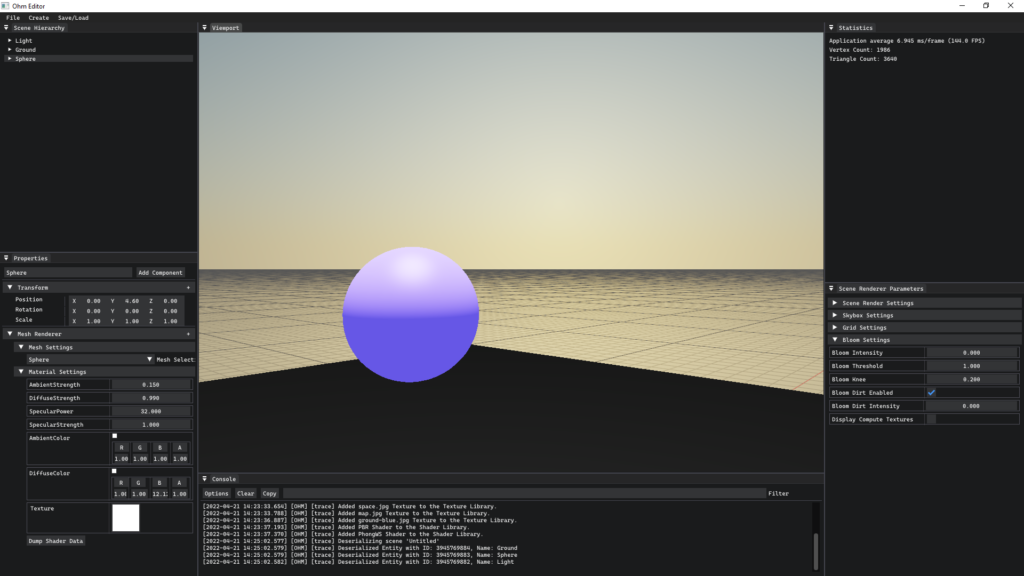
The first tool that comes to mind may be a bit pessimistic at first glance: knowing when your ideas are dumb. Something about the beginning parts of an exciting new project brings an unusual amount of motivation, energy and grandiose ideas! For example, when I started on this Simulation Challenge project, our group opted to do a “bartender” simulation. My initial thought wasn’t, “Let’s give the user the ability to make some simple drinks, let them run around a serve folks”, it was, “I’m going to make a physically realistic simulation of fluid to complement a full-scale realistic bartender simulation with PBR materials and photorealistic graphics!” Of course, this isn’t realistic, but it sure is fun to think about! So the first order of business for me, is to get those ideas out of my system quickly. The best way I can do that is to either sate them, by prototyping those nutty features in a session or two – this is usually just to prove to myself that it’s unrealistic for now – or to really map out everything that would go into implementing them. Again, these are just sobering techniques for the “honeymoon” phase of a project.
The second tool I like to carry around piggy-backs off of the last: breadcrumbs. Somewhere along the way, I go from “Let’s let the user pour fluid with a simple line primitive” to, “Fluid simulation using particles and Laplacian operators”. Now, it isn’t always so easy to remember where I crossed that line separating reality from AAA game feature, so I’ve found it helpful to keep track of my thoughts during this period of early design. The other benefit to keeping track of the thought train that forks off to “Stuck on a feature for weeks”-town is that some of those unrealistic features are really only unrealistic for now. There have been a number of times that I’ve ended up revisiting an idea well into development when it’s been appropriate to either pivot from a current feature or add something fresh. It’s also good to see months into a project that I was at one point really inspired!
The last simple tool that I’m absolutely awful at being consistent with is another really annoying cliché: time management. And I don’t mean, pace-yourself, it’s-a-journey type of management, I mean the you-can’t-allocate-resources-to-save-your-life time management I overestimate certain aspects of a project and underestimate others; I complain about simple, mundane tasks and turn a blind eye to the elephant in the room on a daily basis (refactor that class, seriously, go do it right now!). While I do think there is something to the starving artist trope, I believe there might be something a bit more to the “organized and boring” artist one we don’t often hear about. The times I’ve been the most successful in my short development career have been the times that I’ve been willing to sacrifice time and attention towards the shiny features of my application that I think are cool (they really are, I swear!) to features and tools that have been gasping for air for weeks. There’s also quite a bit to be said about having a semblance of work-life-balance. I have no idea what that is, I just heard that it was valuable.
Ultimately, what I’ve realized is that there’s a beautiful cycle that tends to take place during development that takes longer than a month. Infatuation followed by disinterest, followed by complacency mixed with glimpses of hope, motivation and thoughts of leaving for Mexico, eventually blossoming into the recognition of true progress and the value of hard work, only to be met with more problems to solve, kicking off the cycle anew. But yeah, I’ve been told about that whole work-life-balance thing and how that must fit into that equation somewhere. If you manage to figure out what that looks like, let me know.